

ПР6_Отчёт_ЗаболотниковМЕ_9373
.docx
МИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра информационных систем
отчет
по практической работе №6
по дисциплине «Теория информации, данные, знания»
Тема: Эффективное кодирование. Код Хаффмана
Студент(ка) гр. 9373 |
|
Заболотников М.Е. |
Преподаватель |
|
Писарев И. А. |
Санкт-Петербург
2020
Цель работы
Сформулировать ответы на вопросы с указанием источников информации.
Вопросы по теме 6:
Описать метод Хаффмана.
Какие существуют другие методы кодирования? Дать их сравнительную характеристику.
Укажите правильный вариант ответа. «Если взять два наименее вероятных символа в алфавите, эти два символа получат кодовые слова с максимальной длиной, отличающиеся:
вариант отчета 1: последним символом
вариант отчета 2: первым символом»
Закодировать сообщение методом Хаффмана:
-
Сообщение
1
2
3
4
5
6
7
Вероятность
0.3
0.2
0.2
0.1
0.1
0.05
0.05
Алфавит содержит 7 букв, которые встречаются с вероятностями 0,4; 0,2; 0,1; 0,1; 0,1; 0,05; 0,05. Осуществите кодирование по методу Хаффмана.
Выполнение работы
Оптимальное кодирование Хаффмана.
Для реализации данного алгоритма кодирования необходимо сперва взять два наименее вероятных символа в алфавите – эти два символа получат коды с самой большой длиной, отличающиеся последним знаком. Затем эти два символа объединяют, складывая при этом их вероятности. После этого происходит пересортировка вероятностей так, чтобы сохранился порядок убывания. Данную процедуру повторяют до тех пор, пока суммарная вероятность не окажется равной единице.
После проделанной работы строится дерево, корню которого ставится в соответствие узел, вероятность которого равна 1. Далее каждому узлу приписываются два потомка с вероятностями, которые участвовали в формировании этого узла. Процедура выполняется до достижения узлов с вероятностями исходных символов. Единица присваивается узлу с большей вероятностью, ноль – узлу с меньшей вероятностью. Чтобы понять, какой код получился в итоге у какого символа, нужно спуститься от корня к самому нижнему элементу, по пути «собирая» единички и нолики.
Помимо кода Хаффмана существуют кодирование методом Шеннона и Шеннона-Фано. Преимущество кодирования методом Шеннона-Фано заключается в том, что не нужно строить дерево вероятностей, отчего время кодирования заметно увеличивается. Правда, при кодировании методом Шеннона получаются более эффективные коды.
Если взять два наименее вероятных символа в алфавите, эти два символа получат кодовые слова с максимальной длиной, отличающиеся последним символом.
Решение:
-
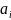
Построение дерева вероятностей
Итоговый код
1
0.3
0.3
0.3
0.3
0.4
0.6
1
?
2
0.2
0.2
0.2
0.3
0.3
0.4
?
3
0.2
0.2
0.2
0.2
0.3
?
4
0.1
0.1
0.2
0.2
?
5
0.1
0.1
0.1
?
6
0.05
0.1
?
7
0.05
?
Построим дерево вероятностей:
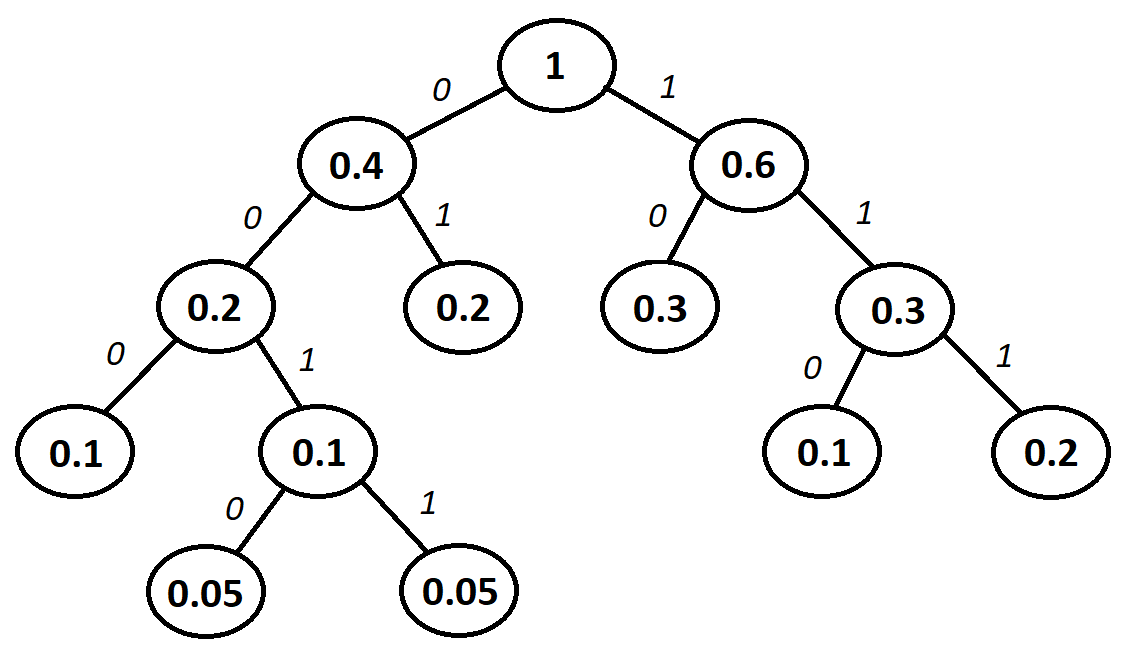
Таким образом, получаем коды для сообщений:
-
Построение дерева вероятностей
Итоговый код
1
0.3
0.3
0.3
0.3
0.4
0.6
1
10
2
0.2
0.2
0.2
0.3
0.3
0.4
01
3
0.2
0.2
0.2
0.2
0.3
111
4
0.1
0.1
0.2
0.2
110
5
0.1
0.1
0.1
000
6
0.05
0.1
0011
7
0.05
0010
Решение:
-
Построение дерева вероятностей
Итоговый код
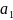
0.4
0.4
0.4
0.4
0.4
0.6
1
?
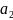
0.2
0.2
0.2
0.2
0.4
0.4
?
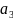
0.1
0.1
0.2
0.2
0.2
?
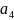
0.1
0.1
0.1
0.2
?
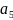
0.1
0.1
0.1
?

0.05
0.1
?
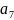
0.05
?
Построим дерево вероятностей:
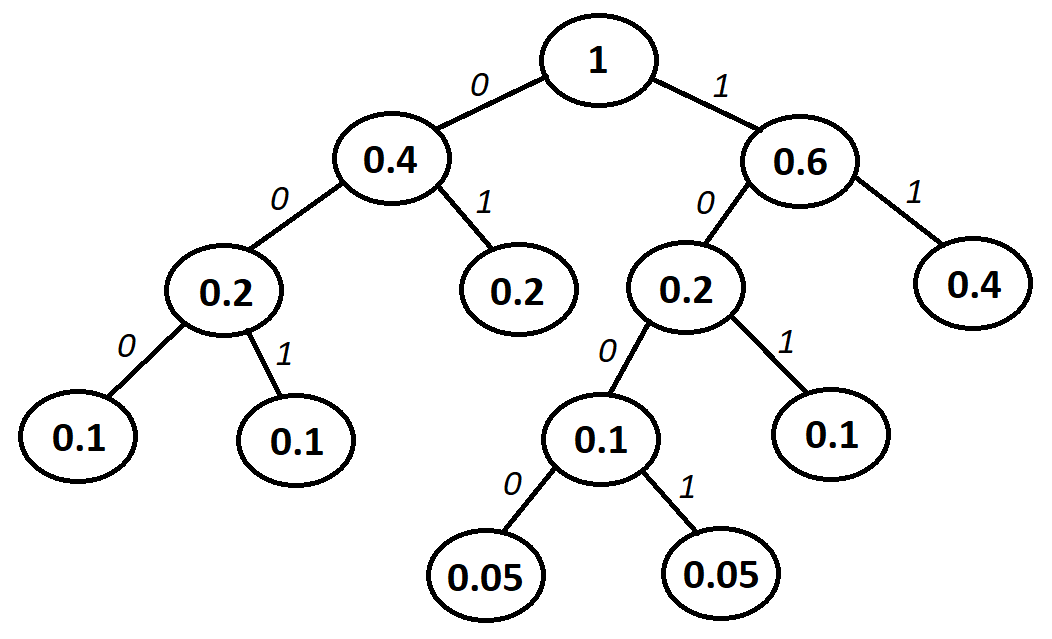
Таким образом, получаем коды букв:
-
Построение дерева вероятностей
Итоговый код
0.4
0.4
0.4
0.4
0.4
0.6
1
11
0.2
0.2
0.2
0.2
0.4
0.4
01
0.1
0.1
0.2
0.2
0.2
101
0.1
0.1
0.1
0.2
001
0.1
0.1
0.1
000
0.05
0.1
1001
0.05
1000
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
https://yadi.sk/i/wthU8ISpHESyQQ