

ПР3_Отчёт_ЗаболотниковМЕ_9373
.docx
МИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра информационных систем
отчет
по практической работе №3
по дисциплине «Теория информации, данные, знания»
Тема: Условно-энтропийный, алгоритмический, семантический и прагматический (ценностный) подходы к определению количества информации.
Студент(ка) гр. 9373 |
|
Заболотников М.Е. |
Преподаватель |
|
Писарев И. А. |
Санкт-Петербург
2020
Цель работы
Сформулировать ответы на вопросы с указанием источников информации.
1. Понятие условной энтропии
2. Сущность алгоритмического подхода к измерению количества информации
3. Формула А. А. Харкевича для оценки ценности информации.
4. Решить две задачи:
4.1. Составить информационный тезаурус по теме «информатика»
4.2. Привести примеры двух последовательностей символов некоторого алфавита и предложить сравнительную оценку количества информации на основе алгоритмического подхода А. Н. Колмогорова
Выполнение работы
Пусть В – случайное событие, тогда p(B) – вероятность его наступления. И пусть есть величина Х, которая может принимать N состояний:
 .
Обозначим через
.
Обозначим через
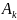 событие того, что Х примет состояние
событие того, что Х примет состояние
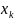 .
Тогда вероятность этого события –
.
Тогда вероятность этого события –
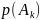 .
Вероятность
.
Вероятность
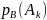 события
,
вычисленная в предположении о том, что
наступило событие В, называется условной
вероятностью события
.
Так вот условной энтропией называется
величина, вычисленная как:
события
,
вычисленная в предположении о том, что
наступило событие В, называется условной
вероятностью события
.
Так вот условной энтропией называется
величина, вычисленная как:
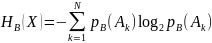 .
.Идея алгоритмического измерения количества информации была выдвинута в 1965 г. А.Н. Колмогоровым. Суть ее заключается в том, что количество информации определяется как минимальная длина программы, позволяющей преобразовать один объект (множество) в другой. последовательность. Этот подход, не базирующийся на понятии вероятности, позволяет, например, определить прирост количества информации, содержащейся в результатах расчета, по сравнению с исходными данными.
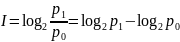 ,
где
,
где
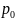 и
и
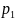 – вероятности достижения цели
соответственно до и после получения
информации.
– вероятности достижения цели
соответственно до и после получения
информации.4.1. Тезаурус по теме «Информатика»:
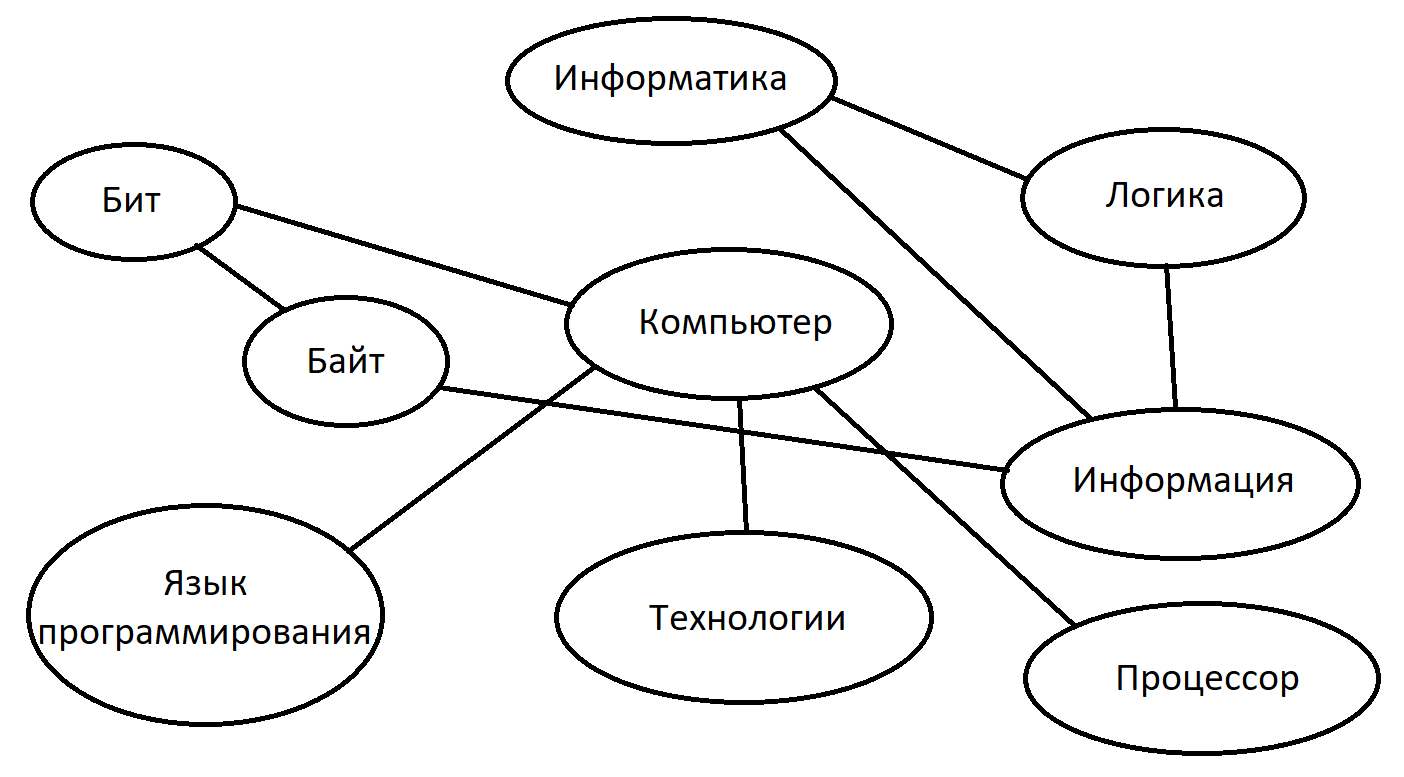
Тезаурус (точнее, его часть) представлена в виде фрагмента тезаурусной сети.
4.2. Пусть у нас имеется алфавит, состоящий из латинских букв: a, b, c, d, e, f, …, и пусть имеются две последовательности этих букв: 1) a, c, e, c, a, c, e, c, a, c, e, …, 2) a, b, c, d, e, x, y, z, a, b, c, d, e, x, y, z, a, b, c, d, … Объём программы, позволяющей воспроизвести первую последовательность, окажется существенно меньше, чем объём программы по воспроизведению второй последовательности, так как во второй последовательности содержится больше разнообразной информации. Делаем такой вывод на основе алгоритма Колмогорова: количество информации во втором сообщении значительно больше, чем в первом.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
https://yadi.sk/i/h7gYkbrSA5S3og
https://yadi.sk/i/g387TDYOrKwdUw