

7. Словарное кодирование. Метод LZW
.docxМИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра информационных систем
отчЁт
по практической работе №7
по дисциплине «Теория информации, данные, знания»
Тема: Словарное кодирование. Метод LZW.
Студент гр. 93— |
|
— |
Преподаватель |
|
Писарев И. А. |
Санкт-Петербург
2020
Цель работы
Сформулировать ответы на вопросы с указанием источников информации.
Вопросы по теме:
В чем состоит особенность методов словарного кодирования.
Дайте сравнительную характеристику наиболее известных методов словарного кодирования (LZ77, LZ78, LZW).
Опишите метод Лемпеля—Зива—Велча (LZW).
Решить задачи:
Закодируйте сообщение «bbbbbbbbbb» методом LZW. Опишите выполненные шаги алгоритма кодирования. Какое значение степени сжатия получено? Приведите описание последовательности выполненных действий по кодированию с комментариями выполняемых шагов алгоритма.
Закодируйте сообщение «DADAADAAA» методом LZW. Опишите выполненные шаги алгоритма кодирования. Какое значение степени сжатия получено? Приведите описание последовательности выполненных действий.
Выполнение работы
Вопрос 1.
Методы, основанные на словарном подходе, не рассматривают статистические модели, они также не используют коды переменной длины. Вместо этого они выбирают некоторые последовательности символов, сохраняют их в словаре, а все последовательности кодируются в виде меток, используя словарь. (1, С. 81)
Вопрос 2.
LZ77
создаётся двигаемое окно в виде строки символов, требующих сжатие;
метки из трёх полей: смещение в буфере поиска, длина совпадающей последовательности, символ в упреждающем буфере;
LZ78
не использует буфер поиска, упреждающий буфер и скользящее окно;
словарь ранее встретившихся строк ограничен объёмом доступной памяти;
метки из двух полей: указатель на строку в словаре, код символа;
LZW
вариант алгоритма LZ78;
метка из одного поля: указатель на место в словаре;
словарь инициализируется всеми символами исходного алфавита.
(1, С. 84—97)
Вопрос 3.
Последовательно считываются символы входного потока и происходит проверка, существует ли в созданной таблице строк такая строка. Если такая строка существует, считывается следующий символ, а если строка не существует, в поток заносится код для предыдущей найденной строки, строка заносится в таблицу, а поиск начинается снова. (2, С. 66)
Задача 1.
Пусть алфавит
состоит из 256 символов, а максимальный
размер словаря — 1024 строки (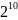 ).
Вход: bbbbbbbbbb —
8 × 10 = 80 бит.
).
Вход: bbbbbbbbbb —
8 × 10 = 80 бит.
Шаги алгоритма:
Входной поток |
Новая запись в словаре |
Выходной поток |
[bbbbbbbbbb] b |
(b уже в словаре) |
|
[bbbbbbbbbb] bb |
256: bb |
98 (b) |
[bbbbbbbbbb] b |
(b уже в словаре) |
|
[bbbbbbbbbb] bb |
(bb уже в словаре) |
|
[bbbbbbbbbb] bbb |
257: bbb |
256 (bb) |
[bbbbbbbbbb] b |
(b уже в словаре) |
|
[bbbbbbbbbb] bb |
(bb уже в словаре) |
|
[bbbbbbbbbb] bbb |
(bbb уже в словаре) |
|
[bbbbbbbbbb] bbbb |
258: bbbb |
257 (bbb) |
[bbbbbbbbbb] b |
(b уже в словаре) |
|
[bbbbbbbbbb] bb |
(bb уже в словаре) |
|
[bbbbbbbbbb] bbb |
(bbb уже в словаре) |
|
[bbbbbbbbbb] bbbb |
(bbbb уже в словаре) |
|
[bbbbbbbbbb] bbbbEOF |
259: bbbbEOF |
258 (bbbb) |
Выход: 98 256 257 258 — 10 × 4 = 40 бит.
Степень сжатия: 80 / 40 = 2.
Задача 2.
Пусть алфавит состоит из 256 символов, а максимальный размер словаря — 1024 строки ( ). Вход: DADAADAAA — 8 × 9 = 72 бита.
Шаги алгоритма:
Входной поток |
Новая запись в словаре |
Выходной поток |
[DADAADAAA] D |
|
|
[DADAADAAA] DA |
256: DA |
68 (D) |
[DADAADAAA] A |
|
|
[DADAADAAA] AD |
257: AD |
65 (A) |
[DADAADAAA] D |
|
|
[DADAADAAA] DA |
|
|
[DADAADAAA] DAA |
258: DAA |
256 (DA) |
[DADAADAAA] A |
|
|
[DADAADAAA] AD |
|
|
[DADAADAAA] ADA |
259: ADA |
257 (AD) |
[DADAADAAA] A |
|
|
[DADAADAAA] AA |
260: AA |
65 (A) |
[DADAADAAA] A |
|
|
[DADAADAAA] AA |
|
|
[DADAADAAA] AAEOF |
261: AAEOF |
260 (AA) |
Выход: 68 65 256 257 65 260 — 10 × 6 = 60 бит.
Степень сжатия: 72 / 60 = 1,2.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
Сэломон Д. Сжатие данных, изображений и звука. М.: Техносфера. 2004. 368 с.
Гошин Е.В. Теория информации и кодирования. Самара: Самарский университет. 2018. 124 с.