

Федеральное государственное автономное образовательное учреждение
высшего профессионального образования
«ОМСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ»
Кафедра «Комплексная защиты информации»
Лабораторная работа
по курсу «Базы данных»
Лабораторная работа №10
Выполнили:
Студентки 2-го курса
гр. …………….
Принял:
Самотуга А.Е.
Омск 2022
Ход работы
Часть 1
Цель: изучить разновидность NoSQL БД и рассмотреть их особенности на примерах.
Задачи:
Выбрать 2 разновидности из NoSQL субд из списка ниже (можно другие,относящиеся к NoSQL)
Развернуть СУБД
Спроектировать и развернуть БД, которая будет содержать информацию о
нескольких связанных объектах. (как минимум должны быть 2-3 объекта, можно взять из самой 1-й лабораторной в 3-м семестре - авторы и книги или другие)
Разработать запросы к БД
Оформить отчет:
а) Теория - описание выбранных СУБД, их особенности и для чего применяются
б) практическая часть - процесс установки, развертывания БД, запросы
Выполнение
OrientDB — графовая СУБД, оснащённая возможностями документоориентированных и объектно-ориентированных. Написана на Java.
Поддерживаемые схемы: less (слабоструктурированные данные), full (строго задаёт обязательные поля) и mixed (смешанная: обязательные + необязательные поля). Имеет систему профилирования безопасности, основанную на пользователях и ролях. Поддерживает транзакции в соответствии с требованиями ACID. Поддерживает Gremlin и ограниченный вариант SQL в качестве языков запросов; поддерживаются хранимые процедуры. Использует собственный алгоритм индексации под названием RB+Tree, сочетающий особенности красно-чёрного дерева и B⁺-дерева, позволяя сбалансировать производительность при операциях обновления и добавления данных. Вместо соединений используется работа в графовом стиле — построение деревьев посредством постоянных указателей между записей и их быстрый обход.
Поставляется с веб-интерфейсом Web-Studio, предназначенном для разработчиков и администраторов баз данных, обеспечивающим визуальное управление базами и работу с запросами.
Плюсы:
Полная поддержка ACID транзакций (Atomicity — атомарность, Consistency — согласованность, Isolation — изолированность, Durability — надежность);
Поддержка подмножества языка SQL для выполнения запросов c использованием конструкции SELECT (OrientDB не является реляционной БД, поэтому в полной мере все возможности SQL не поддерживает);
Поддержка "Хранимых Процедур" на языках SQL и JavaScript;
Поддержка хранения данных без описания предварительной схемы, с описанием полной структуры или в смешанном режиме;
100 % совместима со стандартом TinkerPop Blueprints для графо-ориентированных БД;
Поддержка языка запросов Gremlin;[Источник 3]
Установка:

![]()
Рисунок 1 установка

рисунок 2 создание пользователя
 Рисунок
3 создание таблицы
Рисунок
3 создание таблицы


Рисунок 4 создание классов faculty и group


Рисунок 5 создание таблиц

Рисунок 6 представление таблиц в графовом виде


Рисунок 7 создание связей (рёбер)
Cassandra
Cassandra — колоночная система управления базами данных (СУБД) класса NoSQL (Not Only SQL). Рассчитана на работу с большими массивами данных. Написана в Facebook на Java и передана в 2009 году в фонд Apache Software Foundation. Эта СУБД относится к гибридным NoSQL-решениям, поскольку она сочетает модель хранения данных на базе семейства столбцов с концепцией key-value (ключ-значение). Хранилище само позаботится о проблемах наличия единой точки отказа, отказа серверов и о распределении данных между узлами кластера.
Поддерживаются системы Linux на основе пакетов deb (Debian, Ubuntu) и RPM (Red Hat, CentOS). Для работы Cassandra требуется Java. Сама СУБД устанавливается из репозитория или бинарника.
Apache Cassandra – это децентрализованная распределенная система, состоящая из нескольких узлов, по которым она распределяет данные. В отличие от многих других Big Data решений экосистемы Apache Hadoop (HBase, HDFS), эта СУБД не поддерживает концепцию master/slave (ведущий/ведомый), когда один из серверов является управляющим для других компонентов кластера.
Для распределения элементов данных по узлам Кассандра использует последовательное хэширование, применяя хэш-алгоритм для вычисления хэш-значений ключей каждого элемента данных (имя столбца, ID строки и пр.). Диапазон всех возможных хэш-значений, т.е. пространство ключей, распределяется между узлами кластера так, что каждому элементу данных назначен свой узел, который отвечает за хранение и управление этим элементом данных
Плюсы:
Высокая скорость работы.
Отказоустойчивость и масштабирование.
Гибкая масштабированность
Минусы:
Плохо подходит для проектов, где часто меняются или удаляются данные.
Нет транзакций.
Установка:


Рисунок 8 установка и запуск

рисунок 9 создание бд и таблицы со значениями

рисунок 10 вывод таблицы
![]()

рисунок 11 создание таблицы

рисунок 12 вывод таблицы
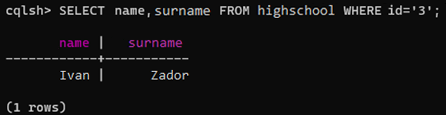
Рисунок 13 вывести имя и фамилию клиента с id 3