

Лабораторная работа №5
.docxМинистерство цифрового развития, связи и массовых коммуникаций
Российской Федерации Ордена Трудового Красного Знамени
федеральное государственное бюджетное образовательное
учреждение высшего образования
Московский технический университет связи и информатики
Кафедра «Математическая кибернетика и информационные технологии»
Лабораторная работа №5
по дисциплине
«Большие данные»
Москва 2022
Оглавление
1. Задание на лабораторную работу 3
2. Выполнение лабораторной работы 4
Задание на лабораторную работу
Установить виртуальную машину HDP Sandbox
Запустить виртуальную машину. В результате запуска она выдает окно с доступом к «менеджеру», похожему на то, что было у Cloudera. Полученные пути нужно открыть на своей хостовой машине. Нам понадобятся как приветствующий экран, так и информация для ssh-подключения
На открывшейся веб-странице выбираем «Launch Dashboard» и в интерфейсе Ambari вводим логин и пароль: maria_dev (одинаковый, для обоих полей ввода). Теперь возможно ознакомится с состоянием сервисов у запущенной виртуальной машины
Среди сервисов необходимо убедится в наличии Spark2 и Zeppelin. Находим второй и среды Quick Links находим Zeppelin UI, он не откроется, но мы сможем узнать, по какому порту необходимо обращаться. Заменяем выделенное на localhost и у нас открывается интерфейс блокнота.
Для переноса файлов с хостовой машины (вашей основной системы) на виртуальную (HDP) необходимо воспользоваться SSH подключением
После копирования файла вы сможете обращаться к нему в виртуальной машине, что и понадобится нам при работе со Spark.
Выполнение лабораторной работы
Чтение и вывод записей представлены на рисунке 1

Рисунок 2 – Чтение и вывод записей
Далее применим фильтр и выведем 10 записей, где поле State == Maine, Полученный результат представлен на рисунке 2.
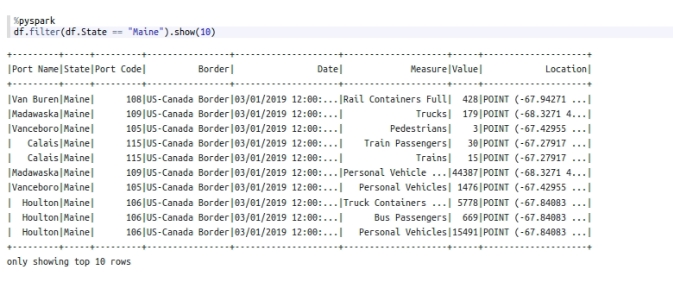
Рисунок 2 – Применение фильтра
Далее произведем группировку поля Value по среднему арифметическому полученный результат представлен на рисунке 3.

Рисунок 3 – Применение группировки
Произведем группировку и агрегацию по полю Port Name. Полученный результат представлен на рисунках 4-5

Рисунок 4 – Группировка и агрегация

Рисунок 5 – Группировка и агрегация
Визуализируем данные при помощи специальной переменной Zeppelin z Результат представлен на рисунках 6 – 7.

Рисунок 6 – Вывод графиков

Рисунок 7 – Вывод графиков