

636_Nosov_V.I._Seti_radiodostupa_CH.1_
.pdfS |
4 |
Z ( 4 ) |
0 |
6 |
12 |
12 |
|
22 |
23 |
29 |
|
|
|
|
|
|
|
|
|
(4.68) |
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
6 |
5 |
5 |
1 |
2 |
1 |
0. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Полученный результат подтверждает, что принятое кодовое слово содержит ошибку (введенную нами), поскольку S ≠ 0.
Локализация ошибки
Допустим, в кодовом слове имеется  ошибок, расположенных на позициях X j1 , X j2 ,..., X j . Тогда полином ошибок, определяемый уравнениями (4.50) и (4.51), можно записать следующим образом
ошибок, расположенных на позициях X j1 , X j2 ,..., X j . Тогда полином ошибок, определяемый уравнениями (4.50) и (4.51), можно записать следующим образом
E(X ) Ej X j1 |
Ej X j2 |
... Ej X j . |
(4.60) |
1 |
2 |
|
|
Индексы 1, 2, ..., обозначают 1-ю, 2-ю, .., |
-ю ошибки, а индекс j — |
||
расположение ошибки. Для коррекции искаженного кодового слова нужно
определить каждое значение ошибки E j |
и ее расположение X jl XJl, где l= 1, 2, |
||||||||||||
|
|
|
|
|
|
l |
|
|
|
|
|
|
|
..., . Обозначим номер локатора ошибки как |
|
l |
jt . Далее вычисляем n - k = |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2t символа синдрома, подставляя |
|
i , в принятый полином при i = 1, 2, ..., 2t. |
|||||||||||
S1 |
Z ( |
) |
|
E j |
1 |
|
E j 2 ... |
E j |
|
|
|||
|
|
|
|
1 |
|
|
2 |
|
|
|
|
|
|
S2 |
Z ( |
2 |
) |
E j |
2 |
|
E j |
|
2 |
... |
E j |
2 |
|
|
1 |
|
|
2 |
(4.61) |
||||||||
|
|
|
|
|
1 |
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
S2t |
Z ( |
2t |
) |
E j |
|
2t |
E j |
|
2t |
... |
|
2t |
|
|
|
1 |
|
2 |
2 |
|
E j |
||||||
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
У нас имеется 2t неизвестных (t значений ошибок и t расположений) и система 2t уравнений. Впрочем, эту систему 2t уравнений нельзя решить обычным путем, поскольку уравнения в ней нелинейные (некоторые неизвестные входят в уравнение в степени). Методика, позволяющая решить эту систему уравнений, называется алгоритмом декодирования кода Рида-Соломона.
Если вычислен ненулевой вектор синдрома (один или более его символов не равны нулю), это означает, что в принятом кодовом слове Z(X) есть ошибка (ошибки). Далее нужно узнать расположение ошибки (или ошибок). Полином локатора ошибок можно определить следующим образом
( X ) |
|
(1 |
1 X )(1 |
2 X )...(1 |
X ) |
|
|
|
|
|
X 2 ... |
|
(4.62) |
1 |
1 |
X |
2 |
X . |
|
|
|
|
|
|
|
||
141

Корнями (Х) будут 1 , 1 ,..., 1 . Величины, обратные корням (Х) ,
1 2
будут представлять номера расположений моделей ошибки E(Х). Тогда, воспользовавшись авторегрессионной техникой моделирования [5], мы составим из синдромов матрицу, в которой первые t синдромов будут использоваться для предсказания следующего синдрома
Воспользуемся авторегрессионной моделью уравнения (4.63), взяв матрицу наибольшей размерности с ненулевым определителем. Для кода (7, 3) с коррекцией двухсимвольных ошибок матрица будет иметь размерность 2 2, и модель запишется следующим образом (4.64)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S1 |
S2 |
|
S3 ... |
St-1 |
St |
|
|
|
|
t |
|
|
|
-St+1 |
|
|
|||||||||
|
S2 |
S3 |
|
S4 ... |
|
St |
St+1 |
|
|
|
t-1 |
|
|
-St+2 |
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
= |
|
|
. |
(4.63) |
||
St-1 |
St |
St+1 ... |
S2t-3 |
S2t-2 |
|
2 |
|
|
|
|
-S2t-1 |
|
|
|||||||||||||
|
St |
St+1 |
St+2 ... |
S2t-2 S2t-1 |
|
1 |
|
|
|
|
-S2t |
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
S1 |
S2 |
|
|
|
2 |
|
|
|
|
|
|
S3 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
= |
|
|
|
|
|
|
|
|
|
|
|
(4.64) |
||
|
|
|
|
|
S2 |
S3 |
|
|
|
1 |
|
|
|
|
|
|
S4 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
= |
|
|
|
|
|
|
|
|
|
|
|
(4.65) |
|||
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Чтобы найти коэффициенты 1 и 2 полинома локатора ошибок (Х), сначала необходимо вычислить обратную матрицу для уравнения (4.65). Обратная матрица для матрицы [А] определяется следующим образом
Inv A |
cofactor A |
. |
|
||
|
det A |
|
Следовательно, |
|
|
142

3 |
5 |
|
|
|
|
|
det |
3 |
6 |
5 |
5 |
9 |
10 |
|
|
|
|
|
|
|
5 |
6 |
|
|
|
|
|
|
|
|
|
|
|
(4.66) |
|
|
2 |
3 |
|
5. |
|
|
3 |
5 |
6 |
5 |
|
|
cofactor |
|
|
|
. |
(4.67) |
|
|
5 |
6 |
5 |
3 |
|
|
|
|
6 |
5 |
|
|
|
3 |
5 |
5 |
3 |
|
6 |
5 |
|
|
|
|
|
||
Inv |
|
|
|
|
5 |
|
|
|
5 |
|
|
|
|
5 |
6 |
|
|
5 |
3 |
|
|
|
|
||||
|
|
|
|
|
|
(4.68) |
6 |
5 |
8 |
7 |
|
1 |
0 |
2 |
|
|
|
|
|
. |
|
|
|
|
|
|
|
5 |
3 |
7 |
5 |
|
0 |
5 |
Проверка надежности
Если обратная матрица вычислена правильно, то произведение исходной и обратной матрицы должно дать единичную матрицу
3 |
5 |
1 |
0 |
4 |
5 |
3 |
10 |
5 |
6 |
5 |
3 |
6 |
6 |
5 |
11 |
1 0
. (4.69)
0 1
С помощью уравнения (4.65) начнем поиск положений ошибок с вычисления коэффициентов полинома локатора ошибок (Х), как показано далее
1 |
0 |
6 |
7 |
0 |
|
2 |
|
|
|
. |
(4.70) |
|
|
0 |
|
||
0 |
5 |
6 |
6 |
|
|
|
|
||||
1 |
|
|
|
|
|
Из уравнений (4.62) и (4.70)
(X ) |
0 |
X |
2 |
X 2 0 6 X 0 X 2. |
(4.71) |
|
1 |
|
|
|
Корни (X) являются обратными числами к положениям ошибок. После того как эти корни найдены, мы знаем расположение ошибок. Вообще, корни (X) могут быть одним или несколькими элементами поля. Определим эти корни путем полной проверки полинома (X) со всеми элементами поля, как
143

будет показано ниже. Любой элемент X, который дает |
(X) = 0, является корнем, |
|||||
что позволяет нам определить расположение ошибки (4.72). |
|
|
|
|
||
Как видно из уравнения (4.62), расположение ошибок является обратной |
||||||
величиной к корням полинома локатора ошибок. А значит, |
|
( |
3) = 0 означает, |
|||
что один корень получается при 1 |
3 . Отсюда |
1 |
|
3 |
4 . Аналогично |
|
|
l |
l |
|
|
|
|
|
|
|
|
|
|
|
( 4) = 0 означает, что другой корень появляется при |
l |
' |
1 4 |
3 где (в |
||
|
|
|
|
|
|
|
данном примере) l и l' обозначают 1-ю и 2-ю ошибки. Поскольку мы имеем дело с 2-символьными ошибками, полином ошибок можно записать следующим образом (4.73)
( |
0 ) |
0 |
6 |
0 |
6 |
0 |
|
|
( |
1 ) |
2 |
7 |
0 |
2 |
0 |
|
|
( |
2 ) |
4 |
8 |
0 |
6 |
0 |
|
|
( |
3 ) |
6 |
9 |
0 |
6 |
0 |
ОШИБКА |
(4.72) |
( |
4 ) |
8 |
10 |
0 |
0 |
ОШИБКА |
|
|
( |
5 ) |
10 |
11 |
0 |
2 |
0 |
|
|
( |
6 ) |
12 |
12 |
0 |
0 |
0 |
|
|
E(X ) Ej X j1 |
Ej X j2 . |
(4.73) |
1 |
2 |
|
Здесь были найдены две ошибки на позициях |
3 и 4. Заметим, что |
|
индексация номеров расположения ошибок является сугубо произвольной. Итак, в этом примере мы обозначили величины
jl |
как |
j1 |
3 и |
j2 |
4. |
l |
|
1 |
|
2 |
|
Значения ошибок |
|
|
|
|
|
Мы обозначили ошибки E j |
, где |
индекс |
j обозначает расположение |
||
|
l |
|
|
|
|
ошибки, а индекс l – l-ю ошибку. Поскольку каждое значение ошибки связано с конкретным месторасположением, систему обозначений можно упростить,
обозначив E j просто как El . Теперь, приготовившись к нахождению значений |
||
l |
|
|
ошибок E1 и E2 связанных с позициями 1 |
3 и 2 |
4 , можно использовать |
любое из четырех синдромных уравнений. Выразим из уравнения (4.61) S1 и
S2
144

S1 |
Z ( ) E1 1 |
E2 2 |
. |
(4.74) |
||||
|
|
|
|
|
|
|
||
S |
Z ( |
2 ) |
E |
2 |
E |
2 |
2 |
|
1 |
|
|
1 |
1 |
2 |
|
|
|
Эти уравнения можно переписать в матричной форме следующим |
||||||||
образом |
|
|
|
|
|
|
|
|
|
1 |
2 |
|
E1 |
|
S1 |
|
(4.75) |
|
1 |
|
2 |
E2 |
|
S2 |
|
|
|
2 |
|
2 |
|
|
|
|
|
|
3 |
|
4 |
E1 |
|
3 |
|
|
|
|
|
|
|
|
|
(4.76) |
|
|
|
|
|
E2 |
|
|
|
|
|
6 |
|
8 |
|
5 |
|
|
|
|
|
|
|
|
|
|||
Чтобы найти значения ошибок E1 и E2 нужно определить обратную матрицу для уравнения (4.76)
|
|
|
|
1 |
4 |
|
1 |
4 |
|
|
|
3 |
4 |
|
|
6 |
3 |
|
6 |
3 |
|
|
|
|
|
|
|
|
|
|
|||||
Inv |
|
|
|
|
|
|
|
|
|
|
|
|
3 |
1 |
6 |
4 |
4 |
3 |
|
|
|||
6 |
1 |
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
(4.77) |
1 |
|
4 |
|
|
1 |
4 |
2 |
5 |
2 |
5 |
|
6 |
|
|
|
1 |
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
6 |
|
3 |
|
|
6 |
3 |
7 |
4 |
0 |
4 |
|
Теперь мы можем найти из уравнения (4.76) значения ошибок
2 |
5 |
3 |
5 |
10 |
2 |
E1 |
|
|
|
|
(4.78) |
E2 |
|
|
|
|
|
|
|
|
|
|
|
0 |
4 |
5 |
3 |
9 |
5 |
Исправление принятого полинома Z(X) с помощью найденного полинома ошибок E(X)
€ |
j1 |
E2 X |
j2 |
2 |
X |
3 |
5 |
X |
4 |
. |
(4.79) |
E(X ) E1X |
|
|
|
|
|
|
145

Показанный алгоритм восстанавливает принятый полином Z(X), выдавая
ˆ |
и в конечном счете, |
в итоге предполагаемое кодовое слово T X |
декодированное сообщение.
Поскольку символы сообщения содержатся в крайних правых k = 3 символах, декодировано будет следующее сообщение
|
|
|
010 |
010 |
010 |
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
1 |
3 |
|
|
5 |
|
|
|
|
|
|
|
|
|
ˆ |
|
ˆ |
|
|
|
ˆ |
|
|
|
|
|
|
|
|
|
|
|
|
T ( X ) |
Z ( X ) E( X ) T ( X ) E( X ) E( X ), |
|
|
|
|
|
|
|
|
|
||||||||
Z ( X ) |
(100) |
(001) X |
(011) X 2 |
(100) X 3 |
(101) X 4 |
(110) X 5 |
|
(111) X 6 , |
|
|||||||||
ˆ |
(000) |
(000) X |
(000) X |
2 |
(001) X |
3 |
(111) X |
4 |
(000) X |
5 |
(000) X |
6 |
, |
|||||
E( X ) |
|
|
|
|
|
|||||||||||||
ˆ |
(100) |
(001) X |
(011) X |
2 |
(101) X |
3 |
|
(010) X |
4 |
(110) X |
5 |
(111) X |
6 |
|
|
|||
T ( X ) |
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
0 |
2 X 4 X 2 |
6 X 3 |
|
|
1 X 4 |
|
3 X 5 5 X 6 . |
|
|
|
(4.80) |
||||||
Это сообщение в точности соответствует тому, которое было выбрано для этого примера (смотри уравнение (4.44)).
Эффективность кодирования – это снижение необходимого отношения Eb/N0 для системы с кодированием по сравнению с системой без кодирования (при одном и том же виде модуляции) для достижения заданной вероятности ошибок. Часто этот параметр называют энергетическим выигрышем кода – ЭВК.
ЭВК Eb / N0 без код. Eb / N0 с код. , дБ. |
(4.81) |
В таблице 4.11 приведены значения ЭВК для некоторых блочных кодов при использовании в гауссовом канале модуляции BPSK, вероятности ошибки 10-5 при отношении Eb/N0.= 9,6 дБ без использования кодирования.
Таблица 4.11 Значения ЭВК блочных кодов
Тип кода |
Хэмминг |
Хэмминг |
Хэмминг |
Голея |
БЧХ |
БЧХ |
|
а |
а |
а |
|
|
|
Парамет |
(7, 4), |
(15, 1), |
(31, 26), |
(24, 12), |
(127, 36), |
(127, 64), |
ры кода |
t = 1 |
t = 1 |
t = 1 |
t = 3 |
t = 15 |
t = 10 |
ЭВК |
0,8 |
1,6 |
1,9 |
2,3 |
2,5 |
3,4 |
|
|
|
146 |
|
|
|
В таблице 4.12 приведены значения требуемого отношения Eb/N0 для блочного кода Рида-Соломона при использовании в гауссовом канале модуляции 32-MFSK с возможностью коррекции t символов и n = 31.
Таблица 4.12 Значения Eb/N0 |
для кода Рида-Соломона |
|
|||
Значения t |
1 |
|
2 |
4 |
8 |
Значения Eb/N0 |
6,15 |
|
5,65 |
5,35 |
5,9 |
147

5. СВЕРТОЧНЫЕ КОДЫ
Блочные коды являются одним из двух видов кодов с коррекцией ошибок, широко используемых при беспроводной передаче. Второй вид – это сверточные коды. Блочный код (п, k) обрабатывает данные блоками по k бит, генерируя на выходе блок из п бит (п > k) для каждого k -битовго блока на входе. Если прием и передача данных происходят относительно непрерывным потоком то блочный код (в частности, с большим значением п) может быть не так удобен как код, который генерирует избыточные биты непрерывно. В последнем случае обнаружение и исправление ошибок выполняется непрерывно, и именно в этом состоит преимущество сверточных кодов[8, 17, 18, 21].
Сверточный код задается тремя параметрами: п, k и К. Код (п, k, К) обрабатывает входящие данные порциями по k бит и генерирует выходную последовательность, состоящую из п бит для каждых k бит входа. До этого момента принципы работы сверточных и блочных кодов не отличаются. Для сверточных кодов п и k, как правило, являются очень малыми числами. Разница между двумя типами кодов состоит в том, что сверточные коды используют память, которая характеризуется длиной кодового ограничения К. По сути, текущая п – битовая входная последовательность кода (п, k, К) зависит не только от значений текущего входного блока, состоящего из k бит, но также и от предыдущих (К -1) k - битовых блоков. Следовательно, текущая выходная п -битовая последовательность является функцией последних (K k) входных битов.
Свѐрточный код создаѐтся прохождением передаваемой информационной последовательности через линейный сдвиговый регистр с конечным числом состояний. В общем, регистр сдвига состоит из К (k -битовых) ячеек и линейного преобразователя, состоящего из п функциональных генераторов и выполняющего алгебраические функции как показано на рисунке. 5.1.
Входные данные к кодеру, которые считаются двоичными, продвигаются вдоль регистра сдвига по k бит за раз. Число выходных битов для каждой k - битовой входной последовательности равно п. Следовательно, кодовая скорость, определѐнная как Rc = k/n, согласуется с определением скорости блочного кода. Параметр К называется длиной кодового ограничения (или кодовым ограничением) свѐрточного кода и указывает число разрядов в регистре сдвига.
5.1 Представление сверточного кодера
Чтобы иметь возможность описывать сверточный код, необходимо определить кодирующую функцию G(m) так, чтобы по данной входной последовательности m можно было быстро вычислить выходную последовательность U. Для реализации сверточного кодирования используется несколько методов; наиболее распространенными из них являются графическая
148
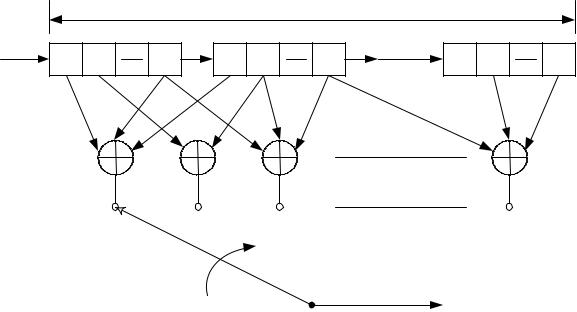
связь, векторы, полиномы связи, диаграмма состояния, древовидная и решетчатая диаграммы. Все они рассматриваются ниже.
Kk ячеек
1 2 |
k |
1 2 |
k |
1 2 |
k |
k |
|
|
|
|
|
информа |
|
|
|
|
|
ционных |
|
|
|
|
|
бит |
|
|
|
|
|
1 |
2 |
3 |
n |
Кодированная последовательность
Рис. 5.1 Сверточный кодер
Представление связи
При обсуждении сверточных кодеров в качестве модели будем использовать сверточный кодер, показанный на рисунке 5.2, а. На этом рисунке изображен сверточный кодер (2, 1, 3) с длиной кодового ограничения К = 3. В нем имеется п =2 сумматора по модулю 2; следовательно, скорость кодирования кода k/n равна 1/2. При каждом поступлении входной бит помещается в крайний левый разряд, а биты регистра смещаются на одну позицию вправо. Затем коммутатор на выходе дискретизирует выходы всех сумматоров по модулю 2 (т.е. сначала верхний сумматор, затем нижний), в результате чего формируются пары кодовых символов, образующих кодовое слово, связанное с только что поступившим битом. Это выполняется для каждого входного бита. На рисунке 5.2, б представлена схема сверточного кодера с параметрами (3, 2, 2).
Выбор связи между сумматорами и разрядами регистра влияет на характеристики кода. Всякое изменение в выборе связей приводит в результате к различным кодам. Связь, конечно же, выбирается и изменяется не произвольным образом. Задача выбора связей, дающая оптимальные дистанционные свойства, сложна и в общем случае не решается; однако для всех значений длины кодового ограничения, меньших 20, с помощью компьютеров были найдены хорошие коды [18].
В отличие от блочных кодов, имеющих фиксированную длину слова п, в сверточных кодах нет определенного размера блока.
149

Вход |
|
|
Выход |
Вход |
|
|
|
|
1 |
Выход |
|
|
|
|
|
2 |
|
||||
1 |
2 |
3 |
|
1 |
2 |
1 |
2 |
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
3 |
|
|
а) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
б) |
|
|
|
|
Рис. 5.2 Сверточный кодер (2, 1, 3) а) и (3, 2, 2) б)
Один из способов реализации кодера заключается в определении п векторов связи, по одному на каждый из п сумматоров по модулю 2. Каждый вектор имеет размерность К и описывает связь регистра сдвига кодера с соответствующим сумматором по модулю 2. Единица на i-й позиции вектора указывает на то, что соответствующий разряд в регистре сдвига связан с сумматором по модулю 2, а нуль в данной позиции указывает, что связи между разрядом регистра и сумматором по модулю 2 не существует Для кодера на рисунке 5.2,а можно записать вектор связи (генераторный полином) g1 для верхних связей, a g2 – для нижних
g1 |
111, |
g2 |
101 |
|
в |
восьмеричной |
форме |
(5.1) |
|
g1 |
7, |
g2 5 |
|
|
Аналогичным образом можно записать генераторные полиномы для кодера на рис. 5.2, б, учитывая, что в этом кодере каждый раз два бита поступают на вход регистров сдвига, а на выходе генерируется три бита
g1 |
1011, |
g2 |
1101, |
|
g3 1010, |
в |
восьмеричной форме |
|
|||
g1 |
13, |
g2 |
15, |
g3 |
12 |
|
|
|
150 |
|
|