

Учебники 80389
.pdfПринцип действия моделирующего компьютера основан на цикле выборки команды, как это показано на рисунке 4.8, либо на цикле выпол-
|
|
|
PC |
|
|
|
|
|
|
|
IR |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
1 0 0 0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
0 0 1 1 1 |
|
|
+ 1 |
|
|
|
1 0 1 0 1 0 0 1 |
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
OP |
операцион- |
|
|
AD адресная |
|
|||||||||||
|
MA |
|
|
|
|
ная |
|
|
|
|
|
|
|
|
|
|
часть |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
дешифратор |
|
|
||||||||||
|
0 |
0 1 |
1 1 |
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 0 |
0 |
|
HLT |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
0 0 |
1 |
|
LDA |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
0 1 |
0 |
|
STA |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
0 1 |
1 |
ADD |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
1 0 |
0 |
SUB |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
1 0 |
1 |
JUN |
|
|
|
|
|
|
||||
адрес |
|
|
|
|
память |
|
|
|
|
|
|
1 0 |
1 |
JUM |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MВ |
|
|
|
|
|
|
||
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
1 0 |
1 |
0 1 |
0 |
0 1 |
|
|
|
|
|
|
|
1 |
|
0 |
|
1 |
0 1 |
|
0 |
0 1 |
||||
7 |
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 4.8. Цикл выборки команды
нения команды, как это видно из рисунка 4.9 Цикл выборки команды. Если допустить, что счетчик команд со-
держит PC (00111)2, то происходит следующее:
1 содержимое PC передается в МА;
2 в содержимое PC добавляется 1;
3 содержимое адреса, на который указывает МА, передается в MB; 4 содержимое MB передается в IR;
5 операционная часть ОР считывается дешифратором (кодом команды является (101) 2, поэтому ОР дешифруется как команда JUN)
Таким образом, при выборке одной команды содержимое счетчика команд PC автоматически увеличивается на единицу, поэтому представляется возможность осуществлять последовательную выборку команд, т. е. обеспечивается последовательное выполнение команд.
|
|
|
|
|
|
|
|
|
|
|
|
|
Цикл выполне- |
|
PC |
|
|
|
|
|
|
|
IR |
ния команды |
|||
|
0 |
1 0 |
0 1 |
|
2 |
|
|
В соответствии с |
|||||
0 |
1 0 |
0 0 |
|
|
|
|
1 0 1 0 1 0 0 1 |
|
командой JUN (см. ри- |
||||
|
1 |
|
|||||||||||
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
OP операционAD адресная |
сунок 4.9) в управляю- |
|||
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
ная |
щее устройство посту- |
|||
|
|
|
|
|
|
|
|
|
|
|
|
пает команда и выпол- |
|
|
|
|
Рис.4.9. Цикл выполнения команды |
няется, поскольку ко- |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
манда |
безусловного |
перехода, содержимое адресной части AD передаются в счетчик команд. Как показано в примере рисунка 4.9, при выполнении команды JUN
адресная часть регистра команды IR [01001]2 передается в счетчик команд
51
и в цикле выборки следующей команды происходит выборка именно той команды адреса (01001)2, которую показывает счетчик команд. В связи с этим не имеет места последовательное управление и происходит "перескок" команды JUN в адрес адресной части AD.
Таким образом, команда JUN используется для перескакивания через несколько команд и представляет собой команду, которая определяет адрес следующей команды.
Команды состоят из трехбитной операционной части и пятибитной адресной части. Из таблицы 4.1 видно, что коды операций имеют семь разновидностей, и для легкости их запоминания используется их мнемоническое представление. Адресная часть AD может задавать адреса от (00)16 до (1F)16 . Такие команды могут непосредственно считываться и выполняться компьютером, поэтому их называют машинными командами.
Распространенные команды загрузки и выгрузки, а также команды (ADD, SUB) действуют опираясь на накапливающий сумматор.
Таблица 4.1.
Коды |
Мнемони- |
|
|
опе- |
ческое |
Действие |
|
обозначе- |
|||
рации |
ние |
|
|
|
|
||
000 |
HLT |
Остановка |
|
001 |
LDA |
Занесение содержимого адреса адресной части AD в накапли- |
|
вающий сумматор АСС |
|||
|
|
||
010 |
STA |
Занесение содержимого накапливающего сумматора АСС в адрес |
|
адресной части AD |
|||
|
|
||
|
|
Суммирование содержимого накапливающего сумматора АСС, |
|
011 |
ADD |
содержимого адреса адресной части AD и хранение полученного |
|
|
|
результата в накапливающем сумматоре АСС |
|
|
|
Вычитание содержимого адреса адресной части AD из содержи- |
|
100 |
SUB |
мого накапливающего сумматора АСС и хранение полученного |
|
|
|
результата в накапливающем сумматоре АСС |
|
101 |
JUN |
Происходит безусловный переход в адрес адресной части AD |
|
|
|
При отрицательном содержимом накапливающего сумматора |
|
110 |
JUM |
АСС происходит «перескок» (при положительном содержимом |
|
|
|
выполняется следующая команда) |
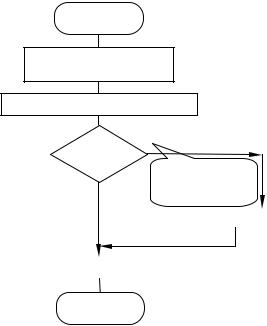
Пример программирования. Необходимо найти меньшее из двух чисел записанных в адресах 1 и 2. Результат поместить в нулевой адрес. Последовательность действия отражает блок схема на рис. 4.10.
Согласно блок-схемы пример программы, составленной с помощью мнемоники, показан в табл. 4.2 позицией 1.
Позиция 2 показывает превращение во внутренний машинный код (программа, которая может выполнятся компьютером), а позицией 3 показан внутренний машинный код в шестнадцатеричном виде.
Программирование на машинном языке. При использовании компь-
ютера, неимеющегооперационнуюсистемуилинеимеющегографического
52
Начало
Адрес 1 → накапливающий сумматор АСС
(АСС) − Адрес 2 → АСС
да
(АСС) < 0
|
|
|
|
|
|
Это тот случай, |
|
|
|
|
||||||
|
|
|
нет |
|
когда меньше |
|
|
|
|
|
|
|||||
|
|
|
|
содержимое адре- |
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
Адрес 2 → АСС |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
Адрес 2 → АСС |
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
(АСС) → нулевой адрес |
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Конец |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 4.10 Блок-схема |
|
|
|
|
|
Таблица 4.2 |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
1 |
|
2 |
|
|
|
3 |
|
|
4 |
|
|
||||
Адрес |
Мнемоника |
|
Машинная |
|
Машинная |
|
Команды |
|
||||||||
(шестнадцате- |
|
|
|
|
команда |
|
|
команда |
ассемблера |
|
||||||
ричный) |
|
|
|
|
(двоичное) |
(шестнадца- |
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
теричное) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ORG |
0 |
|
00 |
0 |
|
000 00000 |
|
|
00 |
|
S |
DS |
1 |
|
|||||
01 |
3 |
|
000 00011 |
|
|
03 |
|
A |
DC |
3 |
|
|||||
02 |
5 |
|
000 00101 |
|
|
05 |
|
B |
DC |
5 |
|
|||||
03 |
|
LDA 1 |
|
001 00001 |
|
|
21 |
|
T |
LDA |
A |
|
||||
04 |
|
SUB 2 |
|
100 00010 |
|
|
82 |
|
|
SUB |
B |
|
||||
05 |
|
JUM 8 |
|
110 01000 |
|
|
C8 |
|
JUM |
M |
|
|||||
06 |
|
LDA 2 |
|
001 00010 |
|
|
22 |
|
|
LDA |
B |
|
||||
07 |
|
JUN 9 |
|
101 01001 |
|
|
A9 |
|
LUN |
ST |
|
|||||
08 |
|
LDA 1 |
|
001 00001 |
|
|
21 |
|
M |
LDA |
A |
|
||||
09 |
|
STA 0 |
|
010 00000 |
|
|
40 |
|
ST |
STA |
S |
|
||||
0A |
|
HLT |
|
000 00000 |
|
|
00 |
|
|
HLT |
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
END |
T |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
монитора, программа должна записываться в восьмеричном или шестнадцатеричном коде (микро ЭВМ, специализированные процессоры). Естественно, программирование ведется с помощью мнемоники и после тщательной отладки программа переводится во внутренний машинный код. При этом следует учитывать адреса команд и данных, что весьма обременительно и приводит к возникновению ошибок.
Язык Ассемблера. Все неудобства машинного языка устраняются ассемблером, который аналогично компиляторам Паскаль, Си и т.д. подготавливает программу на машинном языке путем замены символических
53
имен операций на машинные коды, а символических адресов – на абсолютные или относительные адреса.
В табл. 4.2. позицией 4 показан пример записи программы с использованием псевдокоманд, перечисленных в табл. 4.3
Таблица 4.3
Коды операций |
Операнды |
Описание |
|
|
|
ORG |
n |
Задание адреса начала программы. |
|
|
n - десятичное число! |
DS |
n |
Резервирование области для n – го числа. |
|
|
n - десятичное число! |
DC |
n |
Размещение константы. |
|
|
n - десятичное число! |
END |
1 |
Конец программы. 1 – пусковой адрес программы. |
Латинскими буквами S, T, M обозначены метки, применение которых позволяет осуществлять программирование, не принимая во внимание абсолютные адреса.
Программа на языке ассемблер имеет то достоинство, что программа получается более эффективная и высокоскоростная, чем на языках высокого уровня программирования, но для этого требуется высокая квалификация программиста.
4.5. Процессор, структура и функционирование
В большинстве машин реализованы принципы фон Неймана в следующем виде:
•оперативная память (ОП) организована как совокупность машинных слов (МС) фиксированной длины или разрядности (имеется в виду количество двоичных единиц или бит, содержащихся в каждом МС). Например, ранние ПЭВМ имели разрядность 8, затем появились 16-разрядные, а затем — 32- и 64-разрядные машины. В свое время существовали также 45-разрядные (М-20, М-220), 35-разрядные (Минск-22, Минск-32) и др. машины;
•ОП образует единое адресное пространство, адреса МС возрастают от младших к старшим;
•в ОП размещаются как данные, так и программы, причем в области данных одно слово, как правило, соответствует одному числу, а в области программы - одной команде (машинной инструкции - минимальному и неделимому элементу программы);
•команды выполняются в естественной последовательности (по воз-
растанию адресов в ОП)т пока не встретится команда управления (условного/безусловного перехода, или ветвления - branch), в результате которой естественная последовательность нарушится;
•ЦП может произвольно обращаться к любым адресам в ОП для выборки и/или записи в МС чисел или команд.
Системы команд и соответствующие классы процессоров Основные команды ЭВМ классифицируются вкратце следующим
54
образом (подробнее см. далее, описание команд для i8086): по функциям (выполняемым операциям), направлению приема-передачи информации, адресности.
Классы команд
1.Команды обработки данных, в том числе (O1 - первый операнд, О2
-второй).
1.1.Короткие операции (один такт).
1.1.1. Логические:
•логическое сложение (для каждого бита О1 и О2 осуществляется операция ИЛИ)
•логическое умножение (для каждого бита O1 и О2 осуществляется операция И);
•инверсия (в О1 все единицы заменяются на нули, и наоборот);
•сравнение логическое (если Ol = О2, то некий флаг или регистр устанавливается в «1», иначе в «0»);
1.1.2. Арифметические:
•сложение операндов;
•вычитание (сложение в обратном коде);
•сравнение арифметическое (если О1>О2, или О1 = О2, или О1<О2, то некий флаг или регистр устанавливается в 1, иначе - в 0);
1.2. Длинные операции (несколько тактов):
•сложение/вычитание с фиксированной точкой;
•умножение/деление с фиксированной точкой.
2.Операции управления:
•безусловный переход (ветвление, branch);
•условный переход (по условию, результатам вычислений
(conditional branch)).
3.Операции обращения к внешним устройствам (требование на запись или считывание информации).
Естественно, могут существовать и другие операции - десятичная арифметика, обработка символьной информации, работа с числами половинной (полуслово - например, 16 бит) или двойной (двойное слово - например, 64 бит) длины.
Кроме того, команды различаются по типу выборки и пересылок данных:
•регистр - регистр (О1 и О2 размещаются в регистрах АЛУ);
•память - регистр (регистр - память) - один из операндов размещается в ОП;
•память - память (О1 и О2 размещены в ОП).
Далее, известны одно-, двух- и трехадресные машины (системы команд). Очевидна связь таких параметров ЦУ, как длина адресного пространства, адресность, разрядность. Увеличение разрядности позволяет увеличить адресность команды и длину адреса (т. е. объем памяти, доступной данной команде). Увеличение адресности, в свою очередь, приводит к повышению быстродействия обработки (за счет снижения числа требуемых команд).
В трехадресной машине, например, сложение двух чисел требует од-
55
ной команды (извлечь число по А1, число по А2, сложить и записать результат по A3). В двухадресной необходимы две команды (первая — извлечь число по А1 и поместить в РЧ (или сумматор), вторая — извлечь число по А1, сложить с содержимым РЧ и результат записать по А2). Легко видеть, что одноадресная машина потребует три команды. Поэтому неудивительно, что основная тенденция в развитии ЦУ ЭВМ состоит в увеличении разрядности.
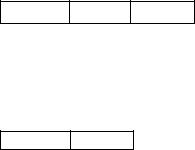
Типовая структура трехадресной команды:
|
КОП |
A1 |
A2 |
A3 |
|
где А2 и A3 - адреса ячеек (регистров), где расположены соответственно пер- |
|||||
вое и второе числа, участвующие в операции; А1 - адрес ячейки (регистра), кудаследуетпоместитьчисло, полученноеврезультатевыполненияоперации.
Типовая структура двухадресной команды:
КОП A1 A2
где А1 - это обычно адрес ячейки (регистра), где хранится первое из чисел, участвующих в операции, и куда после завершения операции должен быть записан результат операции; А2 - обычно адрес ячейки (регистра), где хранится второе участвующее в операции число.
Типовая структура одноадресной команды:
КОП A1
где А1 в зависимости от модификации команды может обозначать либо адрес ячейки (регистра), в которой хранится одно из чисел, участвующих в операции, либо адрес ячейки (регистра), куда следует поместить число —
результат операции.
Безадресная команда содержит только код операции, а информация для нее должна быть заранее помещена в определенные регистры машины.
Наибольшее применение нашли двухадресные системы команд. Таким образом, программирование в машинных адресах требует
знания системы команд конкретной ЭВМ и их адресности. При этом реализация даже довольно несложных вычислений требует разложения их на простые операции, что значительно увеличивает общий объем программы и затрудняет ее чтение и отладку.
Классы процессоров. В зависимости от набора и порядка выполнения команд процессоры подразделяются на четыре класса, отражающих также последовательность развития ЭВМ. Ранее других появились процессоры CISC. Затем, с целью повышения быстродействия процессоров были разработаны процессоры RISC, которые характеризуются сокращенным набором быстро выполняемых команд. Ряд редко встречающихся команд процессора CISC выполняется последовательностями команд процессора RISC. Позже появилась концепция процессоров MISC, использующая минимальный набор длинных команд. Вслед за ними возникли процессоры VLIW, работающие со сверхдлинными командами.
CISC (complex instruction set computer) есть традиционная архитекту-
ра, в которой ЦП использует микропрограммы для выполнения исчерпывающего набора команд. Они могут иметь различную длину, методы адресации и требуют сложных электронных цепей для декодирования и исполнения. В те-
56
чение долгих лет производители компьютеров разрабатывали и воплощали в изделиях все более сложные и полные системы команд. Однако анализ работы процессоров показал, что в течение примерно 80 % времени выполняется лишь20 % большогонаборакоманд. Поэтомубылапоставленазадача оптимизациивыполнениянебольшогопочислу, ночастоиспользуемыхкоманд.
В 1974 г. John Cocke (IBM Research) решил испробовать подход, кото-
рый мог бы существенно уменьшить количество машинных команд в ЦП. В середине 70-х это привело многих производителей компьютеров к пересмотру своихпозицийикразработкеЦПсвесьмаограниченнымнаборомкоманд.
RISC (Redused Instuction Set Computer) - процессор, функционирую-
щий с сокращенным набором команд. Так, в процессоре CISC для выполнения одной команды необходимо в большинстве случаев 10 и более тактов. Что же касается процессоров RISC, то они близки к тому, чтобы выполнять по одной командевкаждомтакте. Следуеттакжеиметьввиду, чтоблагодарясвоейпростоте процессоры RISC не патентуются. Это также способствует их быстрой разработкеиширокомупроизводству. Междутем, всокращенный набор RISC вошли только наиболее часто используемые команды.
Первый процессор RISC был создан корпорацией IBM в 1979 г. и имел шифр IBM 801. В настоящее время процессоры RISC получили широкое распространение. СовременныепроцессорыRISC характеризуютсяследующим:
•упрощенный набор команд, имеющих одинаковую длину;
•большинство команд выполняются за один такт процессора;
•отсутствуют макрокоманды, усложняющие структуру процессора и уменьшающие скорость его работы;
•взаимодействие с оперативной памятью ограничивается операциями пересылки данных;
•резко уменьшено число способов адресации памяти (не используется косвенная адресация);
•используется конвейер команд, позволяющий обрабатывать несколько из них одновременно;
•применяется высокоскоростная память.
Новый подход к архитектуре процессора значительно сократил площадь, требуемую для него на кристалле интегральной схемы. Это позволило резко увеличить число регистров. В современном процессоре RISC уже используется более 100 регистров. В результате процессор на 20-30 % реже обращается к оперативной памяти, что также повысило скорость обработки данных. Упростилась топология процессора, выполняемого в виде одной интегральной схемы, сократились сроки ееразработки, она стала дешевле.
Начиная с процессора Pentium корпорация Intel начала внедрять элементы RISC-технологий в свои изделия.
Процессор MISC - MISC processor, работающий с минимальным набором длинных команд.
Увеличение разрядности процессоров привело к идее укладки нескольких команд в одно слово (связку, bound) размером 128 бит. Оперируя с одним словом, процессор получил возможность обрабатывать сразу несколько команд. Это позволило использовать возросшую производитель-
57
ность компьютера и его возможность обрабатывать одновременно несколько потоков данных.
Процессор MISC, как и процессор RISC, характеризуется небольшим набором чаще всего встречающихся команд. Вместе с этим принцип команд VLIW обеспечивает выполнение группы команд за один цикл работы процессора. Порядок выполнения команд распределяется таким образом, чтобы в максимальной степени загрузить маршруты, по которым проходят потоки данных. Таким образом, архитектура MISC объединила вместе суперскалярную (многопоточную) и VLIW концепции. Компоненты процессора просты и работают с высокими скоростями.
Процессор VLIW - процессор, работающий с системой команд сверхбольшой разрядности.
Идея технологии VLIW заключается в том, что создается специальный компилятор планирования, который перед выполнением прикладной программы проводит ее анализ, и по множеству ветвей последовательности операций определяет группу команд, которые могут выполняться параллельно. Каждая такая группа образует одну сверхдлинную команду. Это позволяет решать две важные задачи. Во-первых, в течение одного такта выполнять группу коротких («обычных») команд. И, во-вторых, упростить структуру процессора. Этим технология VLIW отличается от суперскалярности. В последнем случае отбор групп одновременно выполняемых команд происходит непосредственно в ходе выполнения прикладной программы (а не заранее). Из-за чего усложняется структура процессора и замедляется скорость его работы.
Технология VLIW появилась в результате работ, проведенных корпорациями HP и Intel.
4.6. Структурная схема микропроцессора
Возможности компьютера в большей степени зависят от типа установленного процессора и его тактовой частоты. Семейство процессоров 80х86 корпорации Intel включает в себя микросхемы: 8086, 80186, 80286, 80386, 80486, Pentium, Pentium II, Pentium III и т.д. Совместимые с 80х86
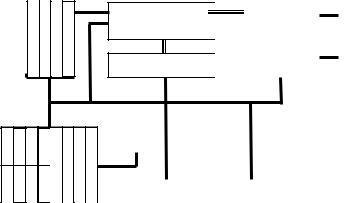
микросхемы выпускают также фирны AMD, IBM, Cyrix. Особенностью этих процессоров является преемственность на уровне машинных команд: программы, написанные для младших моделей процессоров, без какихлибо изменений могут быть выполнены на более старших моделях. При этом базой является система команд процессора 8086, знание которой является необходимой предпосылкой для изучения остальных процессоров. На рис 4.11 приведена структурная схема МП8086.
Устройство управления декодирует байты программы и управляет работой операционного устройства и шинного интерфейса. Операционное устройство МП состоит из 4-х шестнадцатиразрядных регистров общего назначения: РОН (AX, BX, CX, DX), из 4-х регистров указателей (адресных регистров SP, BP, SI, DI) и арифметико-логического устройства (АЛУ) с регистромпризнаков операций (флагов F).
58
0 16 C S D E
S S S S
15
16 16
AX CX 16
0A B C D
L L L L S B S D A B C D P P I I
H H H H
15
BX DX
|
|
|
|
|
4 |
|
|
|
|
ША |
|
сумматор адре- |
|
буфер адресов |
|
||||||
|
|
|
|
|||||||
|
|
|
|
|
||||||
|
сов |
|
|
|
|
|
|
4 |
||
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
ШАД |
|
|
|
|
|
|
|
|
буфер |
|||
|
|
IP |
|
|
16 |
адр / данных |
16 |
|||
|
|
16 |
|
|
|
|
|
16 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16 |
|
|
8 |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
АЛУ |
|
|
|
очередь |
FIFO |
|
|
||
|
|
|
|
|
|
команд |
|
|
||
16 |
9 |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
F |
|
|
|
устр-во |
|
|
|
|
|
|
|
|
|
|
упр-я |
|
|
|
|
15 |
|
0 |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|||
Рис.4.11 структурная схема МП8086.
РОН служат для хранения промежуточных результатов операций, т.е. операндов. Помимо общих, каждый из этих регистров имеет и некоторые специальные функции, о которых будет сказано далее. Каждый РОН может рассматриваться, как состоящий из двух независимых 8-ми разряд-
ных регистров AH, AL, BH, BL, CH, CL и DH, DL.
Адресные регистры хранят 16-ти битовые указатели (адреса) на области памяти. В SP (Stack Pointer) находится текущий адрес "вершины стека" - специально организованной области памяти, которая будет описана далее. Регистр BP(Base Pointer) хранит любой базовый адрес в области стека. Два регистра SI и DI (Source и Destination Index) адресуют области памяти, называемые источником и приемником данных.
МП 8086 имеет 20-ти разрядную шину адреса ША, позволяющую обращаться к 220 или примерно к одному миллиону ячеек памяти. 16-ти битовая шина данных ШД может пересылать информацию байтами или словами. Шинный интерфейс, на рис.5.11 его узлы отмечены двойной чертой, выполняет операции обмена между МП и памятью или внешними устройствами. В сегментных регистрах CS,SS,DS,ES хранятся указатели на 64-х килобайтные области памяти называемые сегментами. Значения этих указателей могут перекрываться. Адрес байта в ячейке памяти получается суммированием содержимого одного из сегментных регистров и одного из регистров (SP,SI,DI,IP). В регистре IP (указателе команд) хранится 16битовый адрес байта в кодовом сегменте к которому микропроцессор должен обратиться. Связь с внешними устройствами осуществляется через специальные тристабильные схемы с повышенной нагрузочной способностью и называемые буферами. Текущий байт программы направляется в очередь команд: шесть однобайтовых регистров расположенных конвейером (по принципу "первым вошел - первым вышел" или FIFO). Конвейер позволяет одновременно выполнять команду из очереди и загружать следующую, повышая производительность МП. Буферные тристабильные элементы увеличивают мощность сигналов до стандартных значений ТТЛ.
По результатам операций АЛУ устанавливает либо сбрасывает отдельные биты в регистре флагов F.
Логические блоки процессора.
59

Структуру центрального процессора Intel 8086 (рис.4.11) можно разделить на два логических блока (рис.4.12):
−блок исполнения (EU:Execution Unit);
−блок интерфейса шин (BIU:Bus Interface Unit).
Интерфейс (interface) - это совокупность средств, обеспечивающих сопряжение устройств и программных модулей как на физическом, так и на логическом уровнях.
В состав EU входят: арифметическо-логическое устройство ALU, устройство управления CU и десять регистров. Устройства блока EU обеспечивают обработку команд, выполнение арифметических и логических операций.
Три части блока BIU - устройство управления шинами, блок очереди команд и регистры сегментов – предназначены для выполнения следующих функций:
−управление обменом данными с EU, памятью и внешними устройствами ввода/вывода;
−адресация памяти;
−выборка команд (осуществляется с помощью блока очереди команд Queue, который позволяет выбирать команды с упреждением).
EU: Execution Unit |
BIU: Bus Interface |
|
AH |
AL |
Unit |
|
||
BH |
BL |
CS |
CH |
CL |
DS |
DH |
DL |
SS |
|
SP |
ES |
BP |
|
|
|
SI |
|
|
DI |
|
Bus Control
Unit
ALU: Arithmetic |
|
|
and Logic Unit |
|
|
CU: Control Unit |
1 |
|
Flags Register |
||
2 |
||
|
||
|
… |
|
Instruction Pointer |
6 |
|
Instruction |
||
|
Queue |
Рис.4.12. Структура центрального процессора.
С точки зрения программиста, процессор 8086 состоит из 8 регистров общего назначения, 4 сегментных регистров, регистра адреса команд (счетчика команд) и регистра флагов. Процессор выставляет на шину адреса адрес выбираемых из памяти команд (или данных), которые поступают в шестибайтный буфер (очередь команд), а затем исполняются.
Адресную шину можно представить в виде 20 проводников, в каждом из которых может либо протекать напряжение заданного уровня (сигнал 1), либо отсутствовать (сигнал 0). Таким образом, микропроцессор
60