

Учебное пособие 2036
.pdfмножество аппроксимаций. Это связано с тем, что алгоритм трассировки лучей не решает так называемое уравнение рендеринга.
Трассировка лучей широко используется во множестве систем визуализации, где применяется для получения удовлетворительных с точки зрения конечного пользователя результатов. Вместе с тем отсутствует решение задачи получения максимально физически корректного результата. Для этого можно обратиться к другому методу – трассировке пути, который является продолжением метода трассировки лучей. Данный метод позволяет получить информацию об изменениях энергии фотона на всем пути в трехмерной сцене, причем, эти изменения происходят с учетом важного физического закона – закона о сохранении энергии, соответственно, результаты метода трассировки пути можно назвать физически корректными. Для их получения для каждого фотона в трехмерной сцене (обычно их существует от нескольких миллионов до десятков миллионов одновременно) необходимо решить уравнение рендеринга [1]. Результат решения этого уравнения определяет цвет конкретного пикселя в результирующем изображении. Текущие аппаратные возможности с архитектурой массового параллелизма не позволяют в полной мере использовать метод трассировки пути, и причин этому несколько, рассмотрим в настоящей работе основные из них.
Первая проблема – поиск точки пересечения луча с геометрией в трехмерной сцене заключается в большом количестве операций при поиске треугольника, с которым луч однозначно пересекается. Даже при малом количестве треугольников в трехмерной сцене при использовании таких оптимизированных алгоритмов, как например, тест T. Müller и B. Trumbore [2], они вс равно в данном случае не дадут нужных результатов в отношении производительности, так как необходимо проверить каждый треугольник в трехмерной сцене для каждого луча. Частично эта проблема решается с помощью использования различных, описывающих трехмерное пространство, структур. Чаще всего используют бинарные деревья (например, иерархия ограничивающих объемов), которые позволяют «отсечь» те треугольники, которые луч однозначно не пересечет, но добавляют вычислительные затраты на бинарный поиск по дереву и прохождение теста пересечения самих описывающих фигур в каждой вершине дерева и затраты на память для хранения этого дерева. Данный подход позволяет в разы ускорить алгоритм поиска точки пересечения, но следует понимать, что процесс построения оптимального дерева может занять больше времени, чем визуализация кадра. Обычный подход построения такого дерева крайне плохо распараллеливается, и перенести его для расч та в GPU (англ. Graphics Processing Unit) довольно сложно, поэтому в данном случае стоит обратить на параллельные подходы, к примеру, построение бинарного дерева с помощью Z-кривой и кодов Мортона [3]. В этом случае, построение можно полностью перенести на графический процессор и существенно уменьшить время выполнения общего алгоритма визуализации.
160
Если говорить об алгоритме поиска треугольника, который пересекается лучом, на графическом процессоре, то стоит упомянуть важную проблему, которая часто проявляется при работе с GPGPU (англ. General-Purpose Computing on Graphics Processing Units): когерентность доступа при чтении глобальной памяти. В соответствии с устройством современных видеокарт, которые имеют большое количество глобальной памяти, его можно использовать для хранения тех же ускоряющих структур, хранения информации о треугольниках сцены, материалов и т.д. Вместе с тем следует заметить, что глобальная память не кэшируется, в отличие от других типов, что означает наличие достаточно сильной задержки при чтении глобальной памяти. Эта задержка может быть тем самым «узким горлышком» в алгоритме трассировки [4], так как необходимо считывать информацию о трехмерной сцене каждый раз, когда выполняется поиск треугольника. Эта проблема также имеет частичное решение: использование типа памяти, которая имеет кэш, к примеру текстурной памяти. Хоть она физически не отделена от глобальной памяти и ограничена по факту только объемом видеопамяти, но имеет ряд существенных отличий. Она хорошо оптимизирована под выборку двумерных данных и имеет особенности в адресации (к примеру, аппаратная поддержка линейной интерполяции данных), а также е части кэшируются на мультипроцессорах, что позволяет уменьшить задержку при непоследовательном чтении.
Следующая проблема, которая затрудняет использование алгоритма трассировки пути в системах визуализации в режиме реального времени, также основана на использовании графических процессоров. Суть ее заключается в том, что при распараллеливании алгоритма трассировки пути, фактическая занятость GPU будет существенно ниже теоретической. Параметр «занятость» показывает, сколько процентов потоков от общего количества делают полезные вычисления, и чем больше это значение – тем лучше. При итеративном подходе трассировки параметр занятости будет в среднем составлять 20%. Это обусловлено тем, что при итеративном подходе, во-первых, используется множество логических ветвей (итеративный подход предполагает использование принципа единого ядра), и часть потоков ожидает, когда вторая часть выполнит свою работу. Во-вторых, при итеративном подходе существует множество точек окончания пути фотона, к примеру, отсутствие пересечения луча в пути с каким-либо треугольником. В таком случае поток также будет ожидать выполнения других потоков, следовательно, для решения проблемы, необходимо каким-либо образом снова занять данные потоки. Например, можно использовать стек лучей, и на каждой итерации назначать одному потоку один существующий луч на обработку, что позволит увеличить занятость, но решит только первый вопрос. Полное решение данной проблемы описано в литературе [5], которая предлагает использовать так называемый подход множества ядер (или волновой подход), при котором весь алгоритм разбивается на множество отдельных вычислительных ядер. В данном случае выделяются в отдельные вычислительные ядра инициализация путей, поиск
161
точки пересечения, вычисление BRDF и BSDF-функций и т.д. В каждом ядре каждый поток работает только с тем путем, который валиден, а небольшой размер ядра позволяет уменьшить время задержки, если по каким-либо причинам часть потоков пойдет по другой логической ветке. В случае, если путь прекращается, то на его месте тут же генерируется новый. Данный подход позволяет уменьшить расходимость потоков, что увеличивает параметр занятости графического процессора. При правильном построении, параметр занятости может достигать 90% - 99% от теоретической оценки для большинства ядер.
Решение вышеописанных проблем может дать приемлемый результат, но при любом подходе результирующее изображение будет иметь сильный шум. Чтобы убрать этот шум необходимо вычислить больше образцов, что минимизирует всю достигнутую производительность. Эта проблема весьма актуальна, так как шум не позволяет использовать алгоритм трассировки пути в системах визуализации. Существует несколько способов его убрать: первый способ заключается в использовании различных методов выборки нового направления луча в пути по определенным параметрам, второй способ заключается в использовании обученных нейронных сетей. Первый способ позволяет еще на этапе вычисления результата пути уменьшить количество путей, которые не достигают источника света, с помощью выбора направления нового луча в зависимости от параметров материала объекта и параметров источника света. К примеру, можно использовать выборку по важности, которая позволяет уменьшить дисперсию случайно величины в методе МонтеКарло, который используется для решения уравнения рендеринга. С практической точки зрения, выборка по важности позволяет больше лучей пускать в сторону источника света (относительно нормали поверхности), которая дает лучшие результаты. Например, на идеально отражающей поверхности только луч, направление которого вычислено по закону отражения, внесет свой вклад в результат. Также, стоит упомянуть и метод явной выборки, при котором на каждом шаге пути пускается дополнительный луч по направлению к источнику света, и если данный луч попадает в источник света, то можно явно сказать, что данная точка на поверхности освещена.
В итоге, результирующее изображение будет иметь в разы меньше шума, хотя некоторые методы (например, метод явной выборки света) добавляют вычислительные издержки. Вместе с тем для достижения полностью бесшумного результата все равно придется вычислять несколько образцов, что не позволяет использовать алгоритм трассировки пути в системах визуализации в режиме реального времени. Поэтому, в качестве второго способа следует рассмотреть использование нейронных сетей. Данный способ лучше всего использовать в совокупности с первым, так как в таком случае можно ожидать хорошие результаты за приемлемое с точки зрения вычислений время. Интересным с данной точки зрения является техника машинного обучения для подавления шума на изображениях, которые были построены с помощью метода трассировки пути Монте-Карло [6], данную технику в качестве основы
162
для расч тов использует компания Nvidia в алгоритме шумоподавления в OptiX AI. Данный метод позволяет очень быстро и качественно убрать шум с результирующего изображения, используя реккурентную нейронную сеть. На вход подается семь скалярных значений: RGB значение пикселя, вектор нормали, глубина и параметр шероховатости. Сама нейронная сеть разбивается на два этапа: в первом этапе – кодирование – применяет дискретизацию на основе выборки, а второй этап – декодирование – применяет повышающую дискретизацию ближайшего соседа, объединяет карты элементов для каждого пикселя, применяет два набора свертки и объединения.
Литература
1.Kajiya J. T. The rendering equation // SIGGRAPH, 1986.– С.143–150
2.Müller T., Trumbore B. Fast, Minimum Storage Ray-Triangle Intersection // Journal of Graphics Tools, 1997.– С.21-28
3.Lauterbach C., Garland M., Sengupta S., Luebke D., Manocha D. Fast BVH Construction on GPUs // EuroGraphics, 2009.– С.375-384
4.Aila T., Laine S. Understanding the Efficiency of Ray Traversal on GPUs // High-Performance Graphics, 2009.– С.145-149
5.Samuli Laine, Tero Karras, Timo Aila Megakernels Considered Harmful: Wavefront Path Tracing on GPUs // High-Performance Graphics, 2013.– С.137-143
6.All Chaitanya C. R., Kaplanyan A., Schield C. Interactive Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoder // ACM Transactions on Graphics, 2017. – С.1-12
АНОО ВО «Воронежский институт высоких технологий», Россия
УДК 004.942
К.А. Маковий, Д.К. Проскурин, Я.В. Метелкин НЕЙРОСЕТЕВОЙ ПОДХОД К ПРОГНОЗИРОВАНИЮ НАГРУЗКИ
ВЦЕНТРАХ ОБРАБОТКИ ДАННЫХ
Вкрупномасштабных центрах обработки данных управление аппаратными ресурсами, которое заключается в организации и распределении их для вычислительных операций и приложений, имеет решающее значение для обеспечения эффективной работы, а также минимизации денежных затрат на обновление и сопровождение.
Нами были предложены способы минимизации первоначальных затрат при внедрении технологии виртуализации [1, 2]. Нагрузка на серверы, как правило, носит циклический характер, так как обычно в организациях существует фиксированный рабочий график, поэтому следующим этапом оптимизации использования серверной инфраструктуры является
163
заблаговременное предсказание характеристик рабочей нагрузки, которое позволяет превентивно контролировать ресурсы в центрах обработки данных, из чего вытекают такие преимущества, как сокращение энергопотребления и повышение производительности. Прогнозирование рабочей нагрузки может быть использовано, например, для определения количества ресурсов, выделяемых для каждого приложения в центре обработки данных в будущем. Точность прогнозирования рабочей нагрузки варьируется в зависимости от используемых методов прогнозирования и характеристик рабочей нагрузки.
Для решения оптимизационных задач в последние годы успешно применяются различные виды биоинспирированных алгоритмов – генетические алгоритмы, искусственные иммунные системы, нейронные сети [3]. В данной работе для прогнозирования нагрузки на сервер предлагается использование нейронной сети (НС). Причиной выбора НС для предсказания нагрузки на сервер является возможность с помощью такого подхода точно прогнозировать данные нелинейных временных рядов.
Целью прогнозирования временных рядов является оценка некоторых будущих значений на основе текущих и прошлых выборочных данных. Математически временной ряд представляет собой последовательность векторов или скаляров y(t), где t представляет прошедшее время. Задача прогнозирования временных рядов состоит в том, чтобы найти функцию f(x) такую, что y'(t) является прогнозируемым значением временного ряда в будущий момент времени:
y'(t) = f(y(t − 1), y(t − 2), y (t − 3), . . .)
Предсказание рядов можно разделить на две категории: линейную и нелинейную. Линейное предсказание временных рядов зависит от линейной комбинации прошлых и текущих значений, однако, большинство реальных приложений прогнозирования временных рядов попадают в категорию нелинейного прогнозирования [4].
Нейросетевой подход, как правило, предлагает предсказание временных рядов без рассмотрения нелинейных данных [5].
Нейронные сети можно разделить на две категории: статические и динамические. Статические (прямые) сети не имеют элементов обратной связи и не содержат временной задержки. Другими словами, выход вычисляется непосредственно с входа через соединения. В динамической сети выход зависит не только от текущего входа, но и от предыдущих входов в сеть или расчетного выхода сети [6].
Рекуррентные НС (RNN) в основном являются прямыми НС (FFNN) с рекуррентным циклом, то есть выходной сигнал подается обратно на вход. Эта модель обычно используется для выполнения многошагового или долгосрочного прогнозирования. В НС с временной задержкой (TDNN) добавляются линии временной задержки (TDL) на вход FFNN. Эта модель обычно используется для прогнозирования временного ряда y(t) на основе его прошлых значений. Определяющим уравнением для TDNN является:
y′(t) = f(y(t − 1), y(t − 2), . . . , y(t − d)),
164

где y'(t) ─ прогнозируемое значение временного ряда, а d ─ временная задержка или память [5,6].
Нами предлагается использование NARX ─ комбинации всех вышеперечисленных НС, которая хорошо подходит для задачи прогнозирования временных рядов. Одним из основных преимуществ таких структур является то, что в качестве входных параметров они могут принимать динамические входные данные, представленные наборами временных рядов. В этой модели значение выходного сигнала вычисляется на основании значений этого сигнала, полученных в предыдущие моменты времени, а также значений управляющего входного сигнала в предыдущие отсчеты времени y(t) и u(t). Определяющее уравнение для второго типа нейронных сетей модель:
y′(t) = f(y(t − 1), . . . , y(t − dy), u(t − 1), . . . , u(t − du)),
где y'(t) - прогнозируемое значение y(t), dy и du представляют входную и выходную временную задержку соответственно. Модель NARX обеспечивает лучший прогноз, чем другие модели НС, поскольку она использует дополнительную информацию, содержащуюся в предыдущих значениях u(t) [6].
Cхема NARX
Разрабатываемая НС состоят из простых элементов (нейронов), работающих параллельно. Значения связей между этими элементами (весами) настраиваются или обучаются для выполнения определенной функции. Сеть настраивается на основе сравнения выхода сети и целевого выхода.
Рабочий процесс для решения задачи путем применения нейросетевого подхода состоит из следующих шагов:
1)сбор данных;
2)предварительная обработка данных;
3)конфигурация НС;
4)обучение НС;
5)испытание НС.
Учитывая эти шаги для задачи прогнозирования загрузки сервера, необходимо получить данных о загрузке ЦОДа, работу которого необходимо оптимизировать. Период, за который берется статистика, а также интервал, с которым она выгружается, выбирается исходя из задачи прогнозирования. Далее эти данные необходимо загрузить, нормировать и преобразовать во временную последовательность.
165
Прогнозирование нагрузки в облачных и кластерных средах является важной задачей для достижения высокой производительности, так как от ее эффективного решения зависит множество процессов, таких как планирование ресурсов, периодичность обслуживания и модернизации.
Литература
1.Makoviy K., Proskurin D., Khitskova Yu., Metelkin Ya. Server hardware resources optimization for virtual desktop infrastructure implementation (Открытый доступ) (2017) CEUR Workshop Proceedings, 1904, pp. 178-183. http://ceur-ws.org/ DOI: 10.18287/1613-0073-2017-1904-178-183
2.Makoviy K. A. et al. A comparison of linear programming and the genetic algorithm approaches to the problem of optimizing the server hardware resources for hosting virtual desktops //Journal of Physics Conference Series. – 2018. – Т. 1096. –
№.1.
3.Astakhova I.F., Ushakov S.A. and Hitskova Ju.V. Model and algorithm of an artificial immune system for the recognition of single symbols / I.F Astakhova., S.A. Ushakov, Ju.V. Hitskova // Advances in Computer Science Proceedings of the 6th European Conference of Computer Science. 2015. С. 127-131.
4.Sapankevych N. I., Sankar R. Time series prediction using support vector machines: a survey //IEEE Computational Intelligence Magazine. – 2009. – Т. 4. –
№.2. – С. 24-38.
5.Mitrea C. A., C. K. M. Lee, Z. A Wu comparison between neural networks and traditional forecasting methods: A case study //International journal of engineering business management. – 2009. – Т. 1. – С. 11.
6.Beale M. H., Hagan M. T., Demuth H. B. Neural network toolbox user’s guide //The MathWorks Inc. – 2018.
ФГБОУ ВО «Воронежский Государственный Технический Университет», Россия
УДК 681.3
Э.И. Воробьев, А.Н. Корякин
РАЗРАБОТКА АЛГОРИТМА ОБРАБОТКИ ВХОДЯЩИХ ОПОВЕЩЕНИЙ В ПОДСИСТЕМЕ МОНИТОРИНГА И АНАЛИЗА РАБОТЫ ОБОРУДОВАНИЯ В РАСПРЕДЕЛЕННОЙ СЕТИ ТЕЛЕКОММУНИКАЦИОННОЙ КОМПАНИИ
В статье рассматриваются вопросы разработки и последующего улучшения алгоритма функционирования подсистемы оповещений в телекоммуникационной компании.
166
Каждая современная телекоммуникационная компания не может обходиться без подсистемы мониторинга и анализа работы оконечного оборудования своей сети. Такие системы обычно делятся на «Performance management» и «Fault management». Performance management включает в себя централизованное отслеживание и использование метрик, полученных с отслеживаемого оборудования [1]. Fault management представляет из себя комплекс программных и аппаратных средств, предназначенных для выполнения действий в случаях отказа. Важнейшей частью подсистемы fault management является механизм оповещений, основная задача которого является довести до сведения системных инженеров о каких-либо аномалиях, произошедших на сети. Большинство современных мониторинговых систем имеют встроенный механизм оповещений.
Источниками оповещений могут являться как правила в Performance management, так и оповещения от внешних систем [2]. Кроме того, источником может являться само устройство, которое отсылает специальный пакет по протоколу SNMP, называемый SNMP-трап. Таким образом, подсистема может получить сразу несколько оповещений, говорящих об одной и той же проблеме. Итогом является то, что сетевой инженер, занимающийся анализом оповещений, будет получать несколько записей, что может вводить в
заблуждение. Поэтому, необходимо разработать единый алгоритм обработки оповещений от всех систем, который будет способен отсекать дубликаты. Важно отметить, что некоторые подсистемы мониторинга умеют отправлять оповещения типа «очистка». Они предназначены для того, чтобы сказать внешней системе, что показатели, которые привели к появлению оповещения, вернулись в рамки нормы и проблема может считаться разреш нной в автоматическом режиме.
Очень часто разрешенные оповещения не удаляются из базы данных, а их помечают специальными полями, или перемещают в отдельную таблицу, хранящую историю оповещений.
Алгоритм необходимо выполнять каждый раз при приходе оповещения перед добавлением его в базу данных. Разработанный алгоритм показан на рисунке.
167
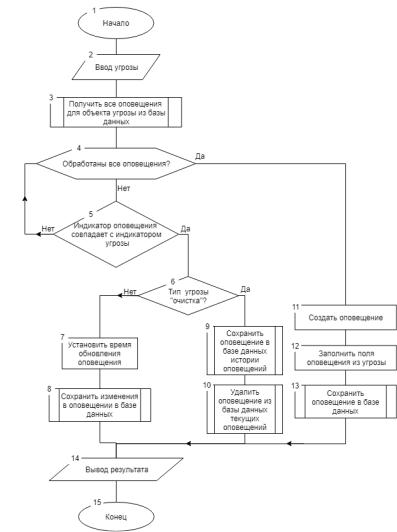
Структурная схема алгоритма анализа входящих угроз
На рисунке показана схема, состоящая из 15 блоков. Входными данными для алгоритма является угроза. Ее ввод показан в блоке 2.
Угроза представляет из себя объект, обычно получаемый из внешней подсистемы. Он содержит несколько специальных полей, тип угрозы, индикатор угрозы, временная отметка, некое описание.
Угроза почти всегда содержит в себе некоторую информацию, которая позволяет идентифицировать устройство, на котором произошло событие, повлекшее появление этой угрозы. Такой информацией может являться уникальный идентификатор устройства, его имя или другая идентифицирующая информация. В блоке 3 производится выборка существующих оповещений из базы данных по идентификатору, полученному из угрозы.
Для каждого полученного оповещения выполняется комплекс проверок с целью идентификации принадлежности угрозы к этому оповещению. Комплекс проверок включает в себя проверку индикатора угрозы и индикатора оповещения. Эта проверка показана в блоке 5. Обычно, анализа индикатора
168
оповещения бывает достаточно чтобы сделать вывод о том, что угроза не имеет отношение к оповещению.
Если связь установлена, тогда необходимо исследовать тип угрозы. Это исследование показано на рисунке в блоке 6.
Если угроза не имеет тип «очистка», то принято обновлять время последнего воспроизведения проблемы. Это обновление показано в блоках 7 и 8.
Если угроза имеет тип «очистка», это означает что оповещение должно считаться исправленным в автоматическом режиме. В текущей реализации, при условии, что угроза имеет тип «очистка», предлагается переносить неактивное оповещение в другую таблицу. Это действие показано на рисунке в блоках 9 и 10.
Если ни одно из текущих оповещений не соответствует пришедшей угрозе, тогда необходимо создать новое оповещение на основе данных, полученных из угрозы. Этот процесс показан на рисунке в блоках 11, 12, 13.
Итогом работы алгоритма является обновление, удаление или создание нового оповещения в базе данных. Далее, эти оповещения может проанализировать сетевой инженер на предмет поиска неисправности, для принятия решений или получения статистики.
Представленный алгоритм является минимально необходимым для каждой подсистемы мониторинга и анализа работы оборудования распределенной компьютерной сети телеком-оператора.
Развитие телекоммуникационных технологий это одно из ключевых сфер в жизни современного общества. Поддержка нормального функционирования сетей стала одной из приоритетнейших задач, поэтому в эту структуру сегодня программисты всего мира пытаются встроить алгоритмы с применением новейших технологий, таких как нейронные сети, генетические алгоритмы, методы вероятностного программирования и многие другие.
В действительности, задача поддержания нормального функционирования оборудования в сети и своевременное предупреждение неисправностей — это отличное поле деятельности для алгоритмов с машинным обучением [3]. В крупных телекоммуникационных компаниях за период работы складывается в базу данным огромное количество оповещений. Если использовать эту базу данных как основу для обучения нейронной сети, то можно получить очень качественного помощника для любого сетевого инженера.
Простейшим примером применения этой технологии является root-cause- analysis. Это специальные алгоритмы, предназначенные для построения зависимостей между отдельными оповещениями. Таким образом, система может делать предположения о том, что, например, скорость на интерфейсе А устройства Б равна нулю потому что интерфейс А переведен в положение «выключено». С точки зрения классической системы эти два оповещения не связаны, так как у них не совпадают индикаторы. Пользователь в этом случаи получит два несвязанных оповещения и может потратить время на поиск
169