

ЛР2_ИМ
.docxМИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
Федеральное государственное автономное образовательное учреждение высшего образования
«САНКТ-ПЕТЕРБУРГСКИЙ УНИВЕРСИТЕТ АЭРОКОСМИЧЕСКОГО ПРИБОРОСТРОЕНИЯ»
КАФЕДРА № 41
ЛАБОРАТОРНАЯ РАБОТА
ЗАЩИЩЕНА С ОЦЕНКОЙ
РУКОВОДИТЕЛЬ
|
ассистент |
|
|
|
М.Н. Шелест |
|
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
|
ОТЧЁТ О ЛАБОРАТОРНОЙ РАБОТЕ №2
|
|
Датчики случайных чисел. Построение гистограмм. |
|
по курсу: ИМИТАЦИОННОЕ МОДЕЛИРОВАНИЕ |
|
|
|
|
РАБОТУ ВЫПОЛНИЛ
|
СТУДЕНТ ГР. № |
4616 |
|
|
|
А.В. Павлов |
|
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург
2019
Цель работы.
Изучение алгоритмов получения на ЭВМ чисел с заданным законом распределения и построения гистограмм.
Вариант задания.
Вариант №7.
Экспоненциальное распределение, = 2
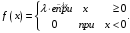
Полученное соотношение из экспоненциального распределения.
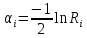
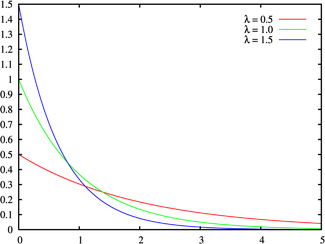
Рисунок 1 – Экспоненциальное распределение
Листинг 1 – Код программы
|
import matplotlib.pyplot as plt import numpy as np import scipy.stats as st #Функция создающая случайные числа def random(lamb,N): alpha = [] #Список сгенерированных чисел for i in range(0,N): R = np.random.uniform(0,1) alpha.append((-1/lamb)*(np.log(R))) return alpha
def main(): dat_list = [] # Массив со всеми сгенерированными значениями lamb = 2 #параметр для распределение step = 100 #шаг Y, mu, D = [], [], [] # Вектор У, для построение гист выборки, МО, дисперсии check = False #Проверка на остановку программы cycle = 1 # количество итераций while check == False: dat_list = dat_list + (random(lamb, step))#Добавляем числа сгенерированных данных в общий список
if cycle == 1 or P >= 0.01: #Проверка на изменение x макс и x мин, дельту x_min = min(dat_list) #Находим минимальный элемент x_max = max(dat_list) #Находим максимальный элемент delta = (x_max - x_min) / 10 #Расчет дельты cycle += 1 #Считаем интервалы и кол. Попаданий в них intervals, count = slicearray(dat_list, delta, x_min, x_max) #Считаем P P = (len(dat_list) - sum(count)) / len(dat_list) #Проверка на условие - кол. попаданий > 100 cnt = 0 for i in count: if i>=100:#Проверка на минимальное попадание в интервал cnt +=1 if cnt==10: check = True #Считаем вектор Y по формуле, for x in range(len(count)): Y.append(count[x] / (len(dat_list) * delta)) #Рисуем график plot(Y, weight, count,mu,D, intervals[:-1:],intervals)
#Считаем МО и Дисперсию mu.append(np.mean(dat_list)) D.append(np.var(dat_list))
def plot(Y,wight,count,mu,D,intervals,exp): x = np.arange(0, len(D), 1) #Генерируем список из кол. элементов print((intervals)) #Вывод интервалов print((count)) #Вывод кол. попаданий xx = np.linspace(min(exp), max(exp), 100) #Генерируем список из кол. элементов #Рисуем гистограмму выборки plt.plot(xx, (st.expon.pdf(xx, loc=0, scale=0.5)),color='red') plt.bar(intervals,Y,width=wight,align='edge') plt.title("Гистограмма выборки") #Рисуем график МО plt.figure(3) plt.plot(x, mu) plt.title("Мат ожидание") # Рисуем график дисперсии plt.figure(4) plt.plot(x, D) plt.title("Дисперсия")
plt.show()
#Функция для разбивки списка на интервалы и подсчета кол. попаданий def slicearray(array,delta,x_min,x_max): interval=[] #список интервалов count = [] #список кол. попаданий #заполняем список интервалов for x in range (0,11): interval.append(x_min + delta * x) for y in range(0,10): summ = 0 for data in array: if y != 10: if interval[y] <= data < interval[y+1]: #Проверяем входит ли этот элемент в этот интервал summ += 1 else: if interval[9] < data <= interval[10]: summ += 1
count.append(summ) return interval, count
main() |
|
|
|
|
Табличное представление распределение элементов выборки по квантам гистограммы.
|
Номер интервала |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Число элементов, попавших в данный интервал |
25608 |
14023 |
7755 |
4256 |
2301 |
1318 |
697 |
427 |
237 |
100 |
Полученные графики

Рисунок 1 –Гистограмма выборки
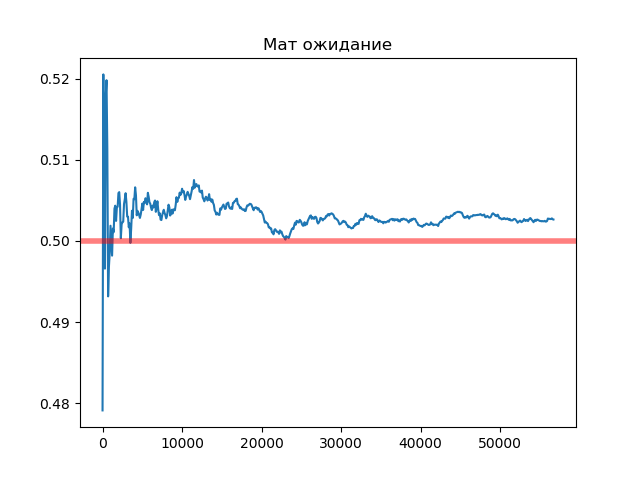
Рисунок 3 – Математическое ожидание
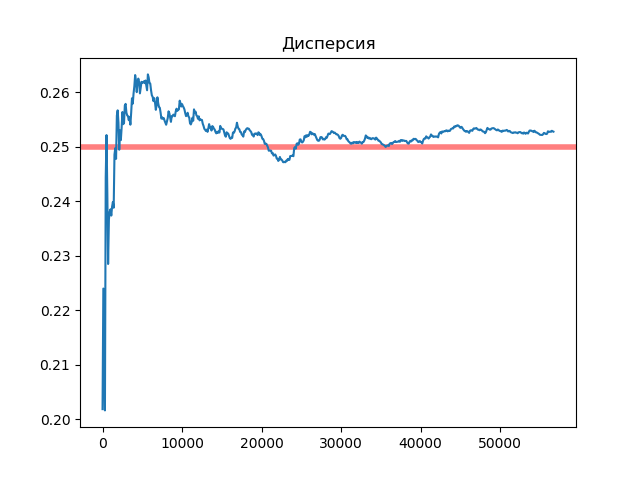
Рисунок 4 - Дисперсия
Выводы.
В ходе данной лабораторной работы мы создали свой датчик случайных чисел с экспоненциальном законом распределением. На основе сгенерированных чисел, нарисовали гистограмму выборки, а так же рассчитали математическое ожидание и дисперсию на каждом этапе генерации. Таким образом на графике видно, что с увеличением выборки наш датчик случайных чисел приближается к истинным значениям экспоненциального распределения. Так например дисперсия в самом большой сгенерированной выборке равна 0.252, а истинное значение 0.25. Мат. Ожидание равно 0.502, а истинное значение 0.5