

8654
.pdfРис. 8. Сборка программы
В случае успешной сборки в окне Output будет выведена соответствующая информация:
=====Build: 1 succeeded, 0 failed, 0 up-to-date, 0 skipped ======
В противном случае следует проверить правильность написанного кода.
2.4. Запуск программы выполняется командой Начать отладку (Start Debugging) из меню Отладка (Debug) см. рис. 9.
Рис. 9. Запуск программы
3. Написание параллельной программы, в которой каждый процесс выводит на экран сообщение: “Hello World!”.
3.1. Перед написанием параллельной программы предварительно необходимо установить среду, включающую в себя библиотеку «mpi», а также средства
для конфигурации вычислительных узлов кластера и запуска параллельных программ. Порядок установки среды MPICH2 от Аргонской национальной лаборатории описан в ПРИЛОЖЕНИИ 1 «Установка среды MPICH2 на вычислительные узлы кластера» настоящих методических указаний.
3.2.Для поддержки параллельных систем будем использовать библиотеку mpi.h. Подключите указанную библиотеку командой include.
3.3.Модифицируйте программу, написанную в Задании 2, добавив в неё функции, создания и завершения параллельной области: MPI_Init() и MPI_Finalize(). Так чтобы код программы принял следующий вид:
#include <mpi.h> #include <stdio.h>
int main(int argc, char* argv[]){ MPI_Init(&argc, &argv);
printf ("Hello World!\n"); MPI_Finalize();
return 0;
}
3.4.Включите поддержку MPI для компилятора через меню Проект – Свойства (Project – Properties). Порядок описан в ПРИЛОЖЕНИИ 2 «Подключение библиотеки MPI в С-проект MS VS2010» настоящих методических указаний.
3.5.Выполните сборку программы как описано в п. 2.3. и в случае успеха запустите программу как описано в п. 2.4. Программа выведет на экран сообщение «Hello World!» 1 раз, как в последовательном варианте программы. Для запуска программы в многопроцессорном режиме необходимо воспользоваться программой «MPIEXEC», входящей в состав среды MPICH2.
3.6.Запустите MPIEXEC из меню Пуск – Программы – MPICH2 (интерфейс показан на рис. 10).

Рис. 10. Интерфейс MPIEXEC
3.7. В поле Application укажите путь к файлу с параллельной программой, в поле Number of processes укажите число процессов, на которых планируется запустить параллельную программу. Установив флажок more options, укажите список вычислительных узлов (hosts), на которых будет запущена параллельная программа, или иные опции (extra mpiexec options). В целях тестирования работоспособности параллельной программы первоначально можно запускать все процессы на локальном компьютере (-localonly) как показано на рис. 11. После задания всех параметров необходимо кнопкой Show Command сформировать командную строку (рис. 11). Запуск параллельной программы выполняется кнопкой Execute.
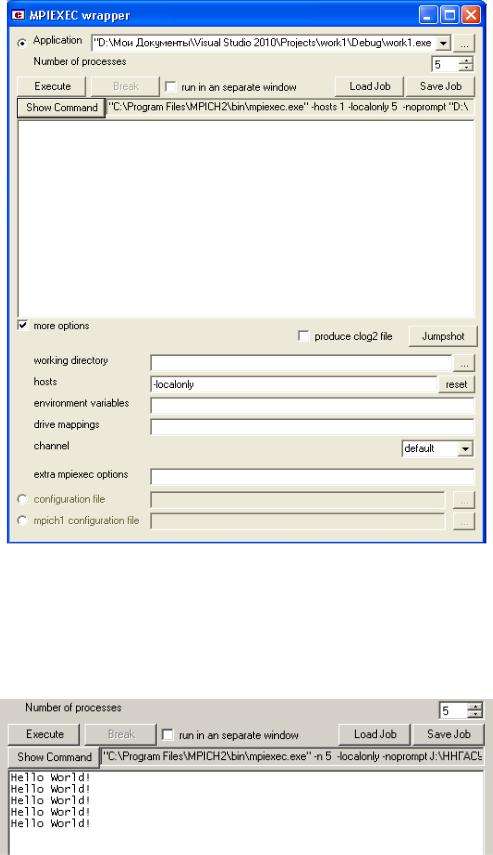
Рис. 11. Запуск программы work1.exe с созданием 5 процессов на одном ПК
В случае успеха каждый процесс выведет на экран сообщение «Hello World!» (рис. 12).
Рис. 12. Результат работы параллельной программы
4. Модификация программы из Задания 3 так, чтобы процессы выводили на экран сообщение: “Hello World!” и свой порядковый номер, а нулевой процесс дополнительно выводил бы количество процессов.
4.1.Для вывода порядковых номеров процессов и их количества необходимо объявить две переменных типа int в функции main().
4.2.Для определения номера потока используйте функцию MPI_Comm_rank(). Для определения количества потоков используйте функцию MPI_Comm_size().
4.3.Все процессы кроме нулевого должны послать свой номер нулевому процессу, а нулевой процесс должен принять номера, посланные другими процессами. Для передачи сообщений между двумя процессами используйте функцию MPI_Send(), а для приёма - MPI_Recv():
MPI_Send(&ProcRank,1,MPI_INT,0,0,MPI_COMM_WORLD);
MPI_Recv(&RecvRank, 1, MPI_INT, MPI_ANY_SOURCE,
MPI_ANY_TAG, MPI_COMM_WORLD, &Status).
Перед использованием функции MPI_Recv() в функции main() необходимо объявить переменную типа int, указывающую на буфер (например, RecvRank), в который процесс будет принимать сообщение, а также переменную типа MPI_Status.
5. Модификация программы из Задания 4 так, чтобы порядковый номер выводился в порядке возрастания.
Для этого в функции MPI_Recv() необходимо указать конкретный номер процесса, от которого выполняется приём сообщения.
6. Запуск параллельной программы на нескольких вычислительных узлах кластера.
Для этого в MPIEXEC в поле hosts укажите список имён вычислительных узлов кластера через пробел. Определить доступные вычислительные узлы можно используя утилиту WMPICONFIG, входящую в состав пакета MPICH2. Порядок определения доступных вычислительных узлов с помощью утилиты WMPICONFIG описан в ПРИЛОЖЕНИИ 3 «Порядок определения доступных вычислительных узлов с помощью утилиты WMPICONFIG» настоящих методических указаний.
ЛАБОРАТОРНАЯ РАБОТА № 2
Тема: Создание консольного многопоточного Windows-приложения, вычисляющего суммы элементов двух n-мерных векторов Ci=Ai+Bi для систем с распределённой памятью.
Цель работы: Изучение mpi-функций приёма и передачи сообщений между двумя процессами, а также широковещательной рассылки.
Лабораторная работа состоит из четырёх последовательно выполняемых заданий.
1.Написать последовательную программу, вычисляющую суммы элементов двух n-мерных векторов Ci=Ai+Bi, где 1 ≤ i ≤ n.
2.Написать параллельную программу на основе технологии MPI, в которой элементы векторов А и В распределяются по процессам и суммируются, при этом n=10, а число процессов равно двум.
3.Модифицировать программу, написанную в Задании 2 так, чтобы она корректно работала с произвольным количеством элементов (n вводится пользователем с клавиатуры) и процессов.
4.Построить графики зависимости времени выполнения последовательного и параллельного алгоритмов от количества элементов вектора и числа процессов. Проанализировать эффективность параллельного алгоритма.
Пояснения к выполнению работы
1. Написание последовательной программы, вычисляющей суммы элементов двух n-мерных векторов Ci=Ai+Bi, где 1 ≤ i ≤ n.
1.1.Создать пустой проект консольного Windows – приложения в среде Visual С++ (см. Лабораторная работа №1).
1.2.Написать код, включающий в себя:
-инициализацию элементов векторов А и В значениями, равными соответствующим номерам элементов векторов;
-вывод на экран значений элементов векторов А и В (функция printf() из библиотеки stdio.h);
-вычисление элементов результирующего вектора С;
-вывод на экран результатов вычислений в виде таблицы.
1.3. Запустить программу.
2. Написание параллельной программы на основе технологии MPI, в которой элементы векторов А и В распределяются по процессам и суммируются, при этом n=10, а число процессов равно двум.
Распараллеливание программы можно выполнить по следующему алгоритму.
2.1.С нулевого процесса разослать всем процессам величину n, используя функцию MPI_Bcast().
2.2.Создать всеми процессами три массива A, B и С с размерностью n.
2.3.Инициализировать элементы массивов A и B значениями и вывести их содержимое на экран на нулевом процессе.
2.4.С нулевого процесса разослать всем процессам содержимое векторов A и B, используя функцию MPI_Bcast().
2.5.Выполнить суммирование элементов векторов A и B, сохранив результаты в вектор C, так чтобы суммирование первых пяти элементов выполнялось на одном процессе, а последних пяти элементов - на другом процессе:
for (i = myid * 5; i < (myid + 1)* 5; i++)
c[i] = a[i] + b[i];
2.6.Собрать результаты суммирования в векторе С на нулевом процессе,
используя функции MPI_Send() и MPI_Recv().
2.7.На нулевом процессе вывести на экран содержимое вектора С.
3. Модификация программы, написанной в Задании 2 так, чтобы она корректно работала с произвольным количеством элементов (n вводится пользователем с клавиатуры) и процессов.
Выполнить самостоятельно.
4. Построение графиков зависимости времени выполнения последовательного и параллельного алгоритмов от количества элементов вектора и числа процессов. Анализ эффективности параллельного алгоритма.
4.1.Добавьте в проект реализацию параллельного и последовательного алгоритмов.
4.2.Выполните замеры времени выполнения всех алгоритмов только для фрагмента кода, выполняющего непосредственное вычисление вектора С. Для измерения времени в последовательном алгоритме можно использовать функцию clock() из библиотеки time.h. Пример использования функции clock() показан ниже:
double t1=clock();// вызывается из последовательной части программы
//Фрагмент кода, в котором необходимо выполнить замер времени double t2=clock();// вызывается из последовательной части
программы
double td=(t2-t1)/double(CLOCKS_PER_SEC);// вычисление разницы между замерами и преобразование результата в секунды
Для измерения времени в параллельном алгоритме можно использовать функцию MPI_Wtime(). Пример использования функции MPI_Wtime() показан ниже:
double start= MPI_Wtime();// вызывается из параллельной части программы
//Параллельный фрагмент кода, в котором необходимо выполнить замер времени
double finish=MPI_Wtime();// вызывается из параллельной части программы
double duration=finish – start;
4.3. Проведите 15 экспериментов, изменяя число процессов и количество элементов векторов так, чтобы для каждой конфигурации вычислительной системы (количества процессов) было выполнено по пять вычислений с
разным количеством элементов векторов. Каждый процесс должен выполняться на одном процессоре (ядре). Количество элементов выбирайте таким образом, чтобы время выполнения алгоритмов составляло не менее 20 секунд. Результаты экспериментов занесите в Таблицу 1.
|
|
|
|
|
Таблица 1 |
|
|
|
|
|
|
|
|
Кол-во |
Кол-во |
Время |
Время |
Ускор |
Эффек |
|
процессов / |
элемен |
выполнения |
выполнения |
ение |
тивнос |
|
вычислител |
тов |
последователь |
параллельного |
(Sp) |
ть (Ep) |
|
ьных узлов |
вектор |
ного |
алгоритма |
|
|
|
кластера |
ов (n) |
алгоритма |
(Tp), сек |
|
|
|
|
|
(T1), сек |
|
|
|
|
2/1 |
|
|
|
|
|
|
2/1 |
|
|
|
|
|
|
2/1 |
|
|
|
|
|
|
2/1 |
|
|
|
|
|
|
2/1 |
|
|
|
|
|
|
4/2 |
|
|
|
|
|
|
4/2 |
|
|
|
|
|
|
4/2 |
|
|
|
|
|
|
4/2 |
|
|
|
|
|
|
4/2 |
|
|
|
|
|
|
6/3 |
|
|
|
|
|
|
6/3 |
|
|
|
|
|
|
6/3 |
|
|
|
|
|
|
6/3 |
|
|
|
|
|
|
6/3 |
|
|
|
|
|
|
4.4. Вычислите ускорение (Sp = T1 / Tp) и эффективность (Ep = Sp / p) параллельной программы. По данным таблицы 1 постройте графики зависимостей ускорения и эффективности от числа процессов, разместив их как показано на рис. 13.
S
6
5
4
N=1000 3 
 N=2000
N=2000
|
N=3000 |
|
2 |
N=4000 |
|
N=5000 |
||
|
||
1 |
|
|
0 |
Число |
|
процессов |
||
|
2 3 4 5 6
Рис. 13 а. Пример графиков зависимости ускорения от числа пороцессов при разных значениях n.
E
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
0.9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
0.8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
0.7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
0.6 |
|
|
|
|
|
|
|
|
|
|
|
N=1000 |
|
|
|
|
|
|
|
|
|
|
|
|
|||
0.5 |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
N=2000 |
||
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
||
0.4 |
|
|
|
|
|
|
|
|
|
|
|
N=3000 |
|
|
|
|
|
|
|
|
|
|
|
||||
0.3 |
|
|
|
|
|
|
|
|
|
|
|
N=4000 |
|
|
|
|
|
|
|
|
|
|
|
|
N=5000 |
||
0.2 |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
||
0.1 |
|
|
|
|
|
|
|
|
|
|
Число |
||
|
|
|
|
|
|
|
|
|
|
||||
0 |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
процессов |
|||
2 |
3 |
4 |
5 |
6 |
|||||||||
|
|
||||||||||||
Рис. 13 б. Пример графиков зависимости эффективности от числа пороцессов при разных значениях n.
4.5. На основе полученных данных проанализируйте эффективность параллельного алгоритма.